About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 296 results for "Michael D. Slater" clear search
Peer reviewed From Individual Fuzzy Cognitive Maps to Agent Based Models: Modeling Multi-Factorial and Multi-stakeholder Decision-Making for Water Scarcity
Sara Mehryar | Published Monday, March 04, 2019 | Last modified Wednesday, August 28, 2019This model simulates different farmers’ decisions and actions to adapt to the water scarce situation. This simulation helps to investigate how farmers’ strategies may impact macro-behavior of the social-ecological system i.e. overall groundwater use change and emigration of farmers. The environmental variables’ behavior and behavioral rules of stakeholders are captured with Fuzzy Cognitive Map (FCM) that is developed with both qualitative and quantitative data, i.e. stakeholders’ knowledge and empirical data from studies. This model have been used to compare the impact of different water scarcity policies on overall groundwater use in a farming community facing water scarcity.
A double-layer network and the contagion mechanism of China’s financial systemic risk
zou | Published Tuesday, August 13, 2019We establish a double-layer network for China’s financial system, consisting of an interbank lending network and a cross-shareholding network. The loss of diffusion in an interbank lending channel independently, a cross-shareholding channel independently and a double-layer contagion channel after one of the financial institutions goes bankrupt with an initial shock are simulated to explore the nonlinear evolution mechanism of financial risk and impact factors of financial systemic risk in China.
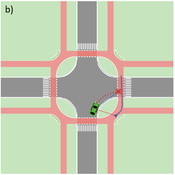
Agent-based Line-of-Sight Simulation for safer Crossings (Short Paper - Netlogo Model)
Vincent Franke | Published Thursday, August 05, 2021This software simulates cars and bicycles as traffic participants while crossing different crossroad designs such as roundabouts, protected crossroads and standard crossroads. It is written in Netlogo 6.2 and aims to identify safety characteristics of these layouts using agent-based modeling. Participants track the line of sight to each other and print them as an output alongside with the adjacent destination, used layout, count of collisions/cars/bicycles and time.
Detailed information can be found within the info tab of the program itself.
Hydroman is a flexible spatially explicit model coupling human and hydrological processes to explore shallow water tables and land cover interactions in flat agricultural landscapes, modeled after the Argentine Pampas. Hydroman aligned well with established hydrological models, and was validated with water table patterns and crop yield observed in the study area.
Confirmation Bias improves Performance in a Signal Detection Task and evolves in an Evolutionary Algorithm
Michael Vogrin | Published Monday, May 08, 2023Confirmation Bias is usually seen as a flaw of the human mind. However, in some tasks, it may also increase performance. Here, agents are confronted with a number of binary Signals (A, or B). They have a base detection rate, e.g. 50%, and after they detected one signal, they get biased towards this type of signal. This means, that they observe that kind of signal a bit better, and the other signal a bit worse. This is moderated by a variable called “bias_effect”, e.g. 10%. So an agent who detects A first, gets biased towards A and then improves its chance to detect A-signals by 10%. Thus, this agent detects A-Signals with the probability of 50%+10% = 60% and detects B-Signals with the probability of 50%-10% = 40%.
Given such a framework, agents that have the ability to be biased have better results in most of the scenarios.
Peer reviewed ABM to create populations with realistic Big Five Personality Trait Expressions
Michael Vogrin | Published Tuesday, May 30, 2023This model aims at creating agent populations that have “personalities”, as described by the Big Five Model of Personality. The expression of the Big Five in the agent population has the following properties, so that they resemble real life populations as closely as possible:
-The population mean of each trait is 0.5 on a scale from 0 to 1.
-The population-wide distribution of each trait approximates a normal distribution.
-The intercorrelations of the Big Five are close to those observed in the Literature.
The literature used to fit the model was a publication by Dimitri van der Linden, Jan te Nijenhuis, and Arnold B. Bakker:
…
The Regional Security Game: An Agent-based, Evolutionary Model of Strategic Evolution and Stability
Anthony Skews | Published Saturday, June 09, 2018The Regional Security Game is a iterated public goods game with punishement based on based on life sciences work by Boyd et al. (2003 ) and Hintze & Adami (2015 ), with modifications appropriate for an international relations setting. The game models a closed regional system in which states compete over the distribution of common security benefits. Drawing on recent work applying cultural evolutionary paradigms in the social sciences, states learn through imitation of successful strategies rather than making instrumentally rational choices. The model includes the option to fit empirical data to the model, with two case studies included: Europe in 1933 on the verge of war and south-east Asia in 2013.
Peer reviewed Behavioral Dynamics of Epidemic Trajectories and Vaccination Strategies: An Agent-Based Model
Ziyuan Zhang | Published Tuesday, December 10, 2024This agent-based model explores the dynamics between human behavior and vaccination strategies during COVID-19 pandemics. It examines how individual risk perceptions influence behaviors and subsequently affect epidemic outcomes in a simulated metropolitan area resembling New York City from December 2020 to May 2021.
Agents modify their daily activities—deciding whether to travel to densely populated urban centers or stay in less crowded neighborhoods—based on their risk perception. This perception is influenced by factors such as risk perception threshold, risk tolerance personality, mortality rate, disease prevalence, and the average number of contacts per agent in crowded settings. Agent characteristics are carefully calibrated to reflect New York City demographics, including age distribution and variations in infection probability and mortality rates across these groups. The agents can experience six distinct health statuses: susceptible, exposed, infectious, recovered from infection, dead, and vaccinated (SEIRDV). The simulation focuses on the Iota and Alpha variants, the dominant strains in New York City during the period.
We simulate six scenarios divided into three main categories:
1. A baseline model without vaccinations where agents exhibit no risk perception and are indifferent to virus transmission and disease prevalence.
…
COVID-19 US Masks
Dale Brearcliffe | Published Sunday, October 18, 2020This model is an abstract simulation of the COVID-19 virus in the United States population. It demonstrates how different masks of different types affect the progress of the virus.
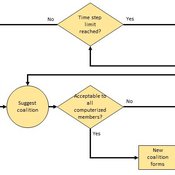
Heuristic Algorithm for Generating Strategic Coalition Structures
Andrew Collins Daniele Vernon-Bido | Published Monday, October 12, 2020The purpose of the model is to generate coalition structures of different glove games, using a specially designed algorithm. The coalition structures can be are later analyzed by comparing them to core partitions of the game used. Core partitions are coalition structures where no subset of players has an incentive to form a new coalition.
The algorithm used in this model is an advancement of the algorithm found in Collins & Frydenlund (2018). It was used used to generate the results in Vernon-Bido & Collins (2021).
Displaying 10 of 296 results for "Michael D. Slater" clear search