About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 1203 results
Consumer diets and values ABM
Natalie Davis Merlin Radbruch | Published Thursday, December 22, 2022 | Last modified Wednesday, March 05, 2025An agent-based model of individual consumers making choices between five possible diets: omnivore, flexitarian, pescatarian, vegetarian, or vegan. Each consumer makes decisions based on personal constraints and values, and their perceptions of how well each diet matches with those values. Consumers can also be influenced by each other’s perceptions via interaction across three social networks: household members, friends, and acquaintances.
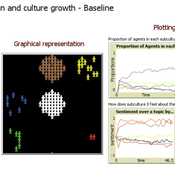
Evolutionary Model of Subculture Choice
Diogo Alves | Published Monday, December 19, 2022This is an original model of (sub)culture diffusion.
It features a set of agents (dubbed “partygoers”) organized initially in clusters, having properties such as age and a chromosome of opinions about 6 different topics. The partygoers interact with a set of cultures (also having a set of opinions subsuming those of its members), in the sense of refractory or unhappy members of each setting about to find a new culture and trading information encoded in the genetic string (originally encoded as -1, 0, and 1, resp. a negative, neutral, and positive opinion about each of the 6 traits/aspects, e.g. the use of recreational drugs). There are 5 subcultures that both influence (through the aforementioned genetic operations of mutation and recombination of chromosomes simulating exchange of opinions) and are influenced by its members (since a group is a weighted average of the opinions and actions of its constituents). The objective of this feedback loop is to investigate under which conditions certain subculture sizes emerge, but the model is open to many other kinds of explorations as well.
Peer reviewed SIM-VOLATILE: Adoption of emerging circular technologies in the waste-treatment sector
Siavash Farahbakhsh | Published Wednesday, December 14, 2022The SIM-VOLATILE model is a technology adoption model at the population level. The technology, in this model, is called Volatile Fatty Acid Platform (VFAP) and it is in the frame of the circular economy. The technology is considered an emerging technology and it is in the optimization phase. Through the adoption of VFAP, waste-treatment plants will be able to convert organic waste into high-end products rather than focusing on the production of biogas. Moreover, there are three adoption/investment scenarios as the technology enables the production of polyhydroxyalkanoates (PHA), single-cell oils (SCO), and polyunsaturated fatty acids (PUFA). However, due to differences in the processing related to the products, waste-treatment plants need to choose one adoption scenario.
In this simulation, there are several parameters and variables. Agents are heterogeneous waste-treatment plants that face the problem of circular economy technology adoption. Since the technology is emerging, the adoption decision is associated with high risks. In this regard, first, agents evaluate the economic feasibility of the emerging technology for each product (investment scenarios). Second, they will check on the trend of adoption in their social environment (i.e. local pressure for each scenario). Third, they combine these two economic and social assessments with an environmental assessment which is their environmental decision-value (i.e. their status on green technology). This combination gives the agent an overall adaptability fitness value (detailed for each scenario). If this value is above a certain threshold, agents may decide to adopt the emerging technology, which is ultimately depending on their predominant adoption probabilities and market gaps.

Peer reviewed Reduced Mobility Transition Model (R-MoTMo)
Gesine A. Steudle Sarah Wolf Steffen Fürst | Published Tuesday, December 06, 2022The Mobility Transition Model (MoTMo) is a large scale agent-based model to simulate the private mobility demand in Germany until 2035. Here, we publish a very much reduced version of this model (R-MoTMo) which is designed to demonstrate the basic modelling ideas; the aim is by abstracting from the (empirical, technological, geographical, etc.) details to examine the feed-backs of individual decisions on the socio-technical system.

Peer reviewed Share: bottom-up disaster information management
Vittorio Nespeca Tina Comes Frances Brazier | Published Monday, December 05, 2022This model is intended to study the way information is collectively managed (i.e. shared, collected, processed, and stored) in a system and how it performs during a crisis or disaster. Performance is assessed in terms of the system’s ability to provide the information needed to the actors who need it when they need it. There are two main types of actors in the simulation, namely communities and professional responders. Their ability to exchange information is crucial to improve the system’s performance as each of them has direct access to only part of the information they need.
In a nutshell, the following occurs during a simulation. Due to a disaster, a series of randomly occurring disruptive events takes place. The actors in the simulation need to keep track of such events. Specifically, each event generates information needs for the different actors, which increases the information gaps (i.e. the “piles” of unaddressed information needs). In order to reduce the information gaps, the actors need to “discover” the pieces of information they need. The desired behavior or performance of the system is to keep the information gaps as low as possible, which is to address as many information needs as possible as they occur.
Schelling Model of the City of Salzburg
Andreas Schlagbauer | Published Monday, December 05, 2022The purpose of the model is to better understand, how different factors for human residential choices affect the city’s segregation pattern. Therefore, a Schelling (1971) model was extended to include ethnicity, income, and affordability and applied to the city of Salzburg. So far, only a few studies have tried to explore the effect of multiple factors on the residential pattern (Sahasranaman & Jensen, 2016, 2018; Yin, 2009). Thereby, models using multiple factors can produce more realistic results (Benenson et al., 2002). This model and the corresponding thesis aim to fill that gap.
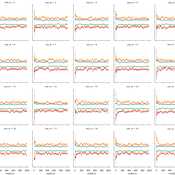
Peer reviewed Dynamic Equilibria Prediction: Experience-Weighted Attraction (EWA), Python Implementation
Vinicius Ferraz | Published Friday, December 02, 2022This project is based on a Jupyter Notebook that describes the stepwise implementation of the EWA model in bi-matrix ( 2×2 ) strategic-form games for the simulation of economic learning processes. The output is a dataset with the simulated values of Attractions, Experience, selected strategies, and payoffs gained for the desired number of rounds and periods. The notebook also includes exploratory data analysis over the simulated output based on equilibrium, strategy frequencies, and payoffs.
NK model for multilevel adaptation
Dario Blanco Fernandez | Published Wednesday, November 30, 2022Previous research on organizations often focuses on either the individual, team, or organizational level. There is a lack of multidimensional research on emergent phenomena and interactions between the mechanisms at different levels. This paper takes a multifaceted perspective on individual learning and autonomous group formation and turnover. To analyze interactions between the two levels, we introduce an agent-based model that captures an organization with a population of heterogeneous agents who learn and are limited in their rationality. To solve a task, agents form a group that can be adapted from time to time. We explore organizations that promote learning and group turnover either simultaneously or sequentially and analyze the interactions between the activities and the effects on performance. We observe underproportional interactions when tasks are interdependent and show that pushing learning and group turnover too far might backfire and decrease performance significantly.
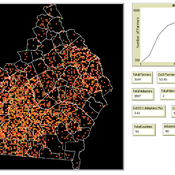
Modelling Farmers’ Adoption Potential to New Bioenergy Crops
Andrew Crooks | Published Tuesday, November 29, 2022A model that representa farmers potential to adopt bio-fuels in Georgia
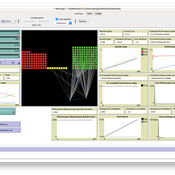
Netlogo Earned Value Management Model
Manuel Castañón-Puga Ricardo Fernando Rosales–Cisneros Julio César Acosta–Prado Alfredo Tirado–Ramos Camilo Khatchikian Elías Aburto–Camacllanqui | Published Thursday, November 24, 2022The model aims to illustrate how Earned Value Management (EVM) provides an approach to measure a project’s performance by comparing its actual progress against the planned one, allowing it to evaluate trends to formulate forecasts. The instance performs a project execution and calculates the EVM performance indexes according to a Performance Measurement Baseline (PMB), which integrates the description of the work to do (scope), the deadlines for its execution (schedule), and the calculation of its costs and the resources required for its implementation (cost).
Specifically, we are addressing the following questions: How does the risk of execution delay or advance impact cost and schedule performance? How do the players’ number or individual work capacity impact cost and schedule estimations to finish? Regardless of why workers cause delays or produce overruns in their assignments, does EVM assess delivery performance and help make objective decisions?
To consider our model realistic enough for its purpose, we use the following patterns: The model addresses classic problems of Project Management (PM). It plays the typical task board where workers are assigned to complete a task backlog in project performance. Workers could delay or advance in the task execution, and we calculate the performance using the PMI-recommended Earned Value.
Displaying 10 of 1203 results