About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 194 results Data clear search
Artificial Long House Valley-Black Mesa
Amy Warren Lisa Sattenspiel | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.

MEGADAPT - Socio-hydrological risk model - Theoretical (no data) implementation
Andres Baeza-Castro Luis Bojorquez Marco Janssen Hallie Eakin | Published Wednesday, February 06, 2019The model simulates the decisions of residents and a water authority to respond to socio-hydrological hazards. Residents from neighborhoods are located in a landscape with topographic complexity and two problems: water scarcity in the peripheral neighborhoods at high altitude and high risk of flooding in the lowlands, at the core of the city. The role of the water authority is to decide where investments in infrastructure should be allocated to reduce the risk to water scarcity and flooding events in the city, and these decisions are made via a multi-objective site selection procedure. This procedure accounts for the interdependencies and feedback between the urban landscape and a policy scenario that defines the importance, or priorities, that the authority places on four criteria.
Neighborhoods respond to the water authority decisions by protesting against the lack of investment and the level of exposure to water scarcity and flooding. Protests thus simulate a form of feedback between local-level outcomes (flooding and water scarcity) and higher-level decision-making. Neighborhoods at high altitude are more likely to be exposed to water scarcity and lack infrastructure, whereas neighborhoods in the lowlands tend to suffer from recurrent flooding. The frequency of flooding is also a function of spatially uniform rainfall events. Likewise, neighborhoods at the periphery of the urban landscape lack infrastructure and suffer from chronic risk of water scarcity.
The model simulates the coupling between the decision-making processes of institutional actors, socio-political processes and infrastructure-related hazards. In the documentation, we describe details of the implementation in NetLogo, the description of the procedures, scheduling, and the initial conditions of the landscape and the neighborhoods.
This work was supported by the National Science Foundation under Grant No. 1414052, CNH: The Dynamics of Multi-Scalar Adaptation in Megacities (PI Hallie Eakin).

AnimDens NetLogo
Miguel Pais Christine Ward-Paige | Published Friday, February 10, 2017 | Last modified Sunday, February 23, 2020The model demonstrates how non-instantaneous sampling techniques produce bias by overestimating the number of counted animals, when they move relative to the person counting them.
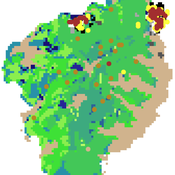
FNNR-ABM
Judy Mak | Published Thursday, February 28, 2019 | Last modified Saturday, December 07, 2019FNNR-ABM is an agent-based model that simulates human activity, Guizhou snub-nosed monkey movement, and GTGP-enrolled land parcel conversion in the Fanjingshan National Nature Reserve in Guizhou, China.
Quick-start guide:
1. Install Python and set environmental path variables.
2. Install the mesa, matplotlib (optional), and pyshp (optional) Python libraries.
3. Configure fnnr_config_file.py.
…
NetLogo HIV spread model
Wouter Vermeer | Published Friday, October 25, 2019This model describes the tranmission of HIV by means of unprotected anal intercourse in a population of men-who-have-sex-with-men.
The model is parameterized based on field data from a cohort study conducted in Atlanta Georgia.
An agent-based model to simulate meat consumption behaviour of consumers in Britain
Andrea Scalco | Published Friday, October 18, 2019The current rate of production and consumption of meat poses a problem both to peoples’ health and to the environment. This work aims to develop a simulation of peoples’ meat consumption behaviour in Britain using agent-based modelling. The agents represent individual consumers. The key variables that characterise agents include sex, age, monthly income, perception of the living cost, and concerns about the impact of meat on the environment, health, and animal welfare. A process of peer influence is modelled with respect to the agents’ concerns. Influence spreads across two eating networks (i.e. co-workers and household members) depending on the time of day, day of the week, and agents’ employment status. Data from a representative sample of British consumers is used to empirically ground the model. Different experiments are run simulating interventions of application of social marketing campaigns and a rise in price of meat. The main outcome is the average weekly consumption of meat per consumer. A secondary outcome is the likelihood of eating meat.
07 EffLab_V5.07 NL
Garvin Boyle | Published Monday, October 07, 2019EffLab was built to support the study of the efficiency of agents in an evolving complex adaptive system. In particular:
- There is a definition of efficiency used in ecology, and an analogous definition widely used in business. In ecological studies it is called EROEI (energy returned on energy invested), or, more briefly, EROI (pronounced E-Roy). In business it is called ROI (dollars returned on dollars invested).
- In addition, there is the more well-known definition of efficiency first described by Sadi Carnot, and widely used by engineers. It is usually represented by the Greek letter ‘h’ (pronounced as ETA). These two measures of efficiency bear a peculiar relationship to each other: EROI = 1 / ( 1 - ETA )
In EffLab, blind seekers wander through a forest looking for energy-rich food. In this multi-generational world, they live and reproduce, or die, depending on whether they can find food more effectively than their contemporaries. Data is collected to measure their efficiency as they evolve more effective search patterns.
…
An Individual-Based Mechanistic Model of Mussel Bed Boundary Formation and Intensity
Matthew Schumm | Published Saturday, September 28, 2019Individually parameterized mussels (Mytilus californianus) recruit, grow, move and die in a 3D environment while facing predation (in the form of seastar agents), heat and desiccation with increased tide height, and storms. Parameterized with data collected by Wootton, Paine, Kandur, Donahue, Robles and others. See my 2019 CoMSES video presentation to learn more.
Crowdworking Model
Georg Jäger | Published Wednesday, September 25, 2019The purpose of this agent-based model is to compare different variants of crowdworking in a general way, so that the obtained results are independent of specific details of the crowdworking platform. It features many adjustable parameters that can be used to calibrate the model to empirical data, but also when not calibrated it yields essential results about crowdworking in general.
Agents compete for contracts on a virtual crowdworking platform. Each agent is defined by various properties like qualification and income expectation. Agents that are unable to turn a profit have a chance to quit the crowdworking platform and new crowdworkers can replace them. Thus the model has features of an evolutionary process, filtering out the ill suited agents, and generating a realistic distribution of agents from an initially random one. To simulate a stable system, the amount of contracts issued per day can be set constant, as well as the number of crowdworkers. If one is interested in a dynamically changing platform, the simulation can also be initialized in a way that increases or decreases the number of crowdworkers or number of contracts over time. Thus, a large variety of scenarios can be investigated.
Displaying 10 of 194 results Data clear search