About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 112 results for "Yunnan University" clear search
Superiority Bias and Communication Noise in a Model of Collective Problem Solving
Amin Boroomand Paul Smaldino | Published Sunday, May 01, 2022This model aims to examine how different levels of communication noise and superiority bias affect team performance when solving problems collectively. We used a networked agent-based model of collective problem solving in which agents explore the NK landscape for a better solution and communicate with each other regarding their current solutions. We compared the team performance in solving problems collectively at different levels of self-superiority bias when facing simple and complex problems. Additionally, we addressed the effect of different levels of communication noise on the team’s outcome
The Internal Organizational Plasticity Model (IOP 2.1.2)
Davide Secchi | Published Tuesday, June 02, 2020IOP 2.1.2 is an agent-based simulation model designed to explore the relations between (1) employees, (2) tasks and (3) resources in an organizational setting. By comparing alternative cognitive strategies in the use of resources, employees face increasingly demanding waves of tasks that derive by challenges the organization face to adapt to a turbulent environment. The assumption tested by this model is that a successful organizational adaptation, called plastic, is necessarily tied to how employees handle pressure coming from existing and new tasks. By comparing alternative cognitive strategies, connected to ‘docility’ (Simon, 1993; Secchi, 2011) and ‘extended’ cognition (Clark, 2003, Secchi & Cowley, 2018), IOP 2.1.2 is an attempt to indicate which strategy is most suitable and under which scenario.
FNNR-ABM
Judy Mak | Published Thursday, February 28, 2019 | Last modified Saturday, December 07, 2019FNNR-ABM is an agent-based model that simulates human activity, Guizhou snub-nosed monkey movement, and GTGP-enrolled land parcel conversion in the Fanjingshan National Nature Reserve in Guizhou, China.
Quick-start guide:
1. Install Python and set environmental path variables.
2. Install the mesa, matplotlib (optional), and pyshp (optional) Python libraries.
3. Configure fnnr_config_file.py.
…

Peer reviewed Social Consequences of Past Compound Events - Laacher See Eruption
Kevin Su Brennen Bouwmeester | Published Monday, May 17, 2021Resilience of humans in the Upper Paleolithic could provide insights in how to defend against today’s environmental threats. Approximately 13,000 years ago, the Laacher See volcano located in present-day western Germany erupted cataclysmically. Archaeological evidence suggests that this is eruption – potentially against the background of a prolonged cold spell – led to considerable culture change, especially at some distance from the eruption (Riede, 2017). Spatially differentiated and ecologically mediated effects on contemporary social networks as well as social transmission effects mediated by demographic changes in the eruption’s wake have been proposed as factors that together may have led to, in particular, the loss of complex technologies such as the bow-and-arrow (Riede, 2014; Riede, 2009).
This model looks at the impact of the interaction between climate change trajectory and an extreme event, such as the Laacher See eruption, on the generational development of hunter-gatherer bands. Historic data is used to model the distribution and population dynamics of hunter-gatherer bands during these circumstances.
RecovUS: An Agent-Based Model of Post-Disaster Household Recovery
Saeed Moradi | Published Thursday, July 30, 2020The purpose of this model is to explain the post-disaster recovery of households residing in their own single-family homes and to predict households’ recovery decisions from drivers of recovery. Herein, a household’s recovery decision is repair/reconstruction of its damaged house to the pre-disaster condition, waiting without repair/reconstruction, or selling the house (and relocating). Recovery drivers include financial conditions and functionality of the community that is most important to a household. Financial conditions are evaluated by two categories of variables: costs and resources. Costs include repair/reconstruction costs and rent of another property when the primary house is uninhabitable. Resources comprise the money required to cover the costs of repair/reconstruction and to pay the rent (if required). The repair/reconstruction resources include settlement from the National Flood Insurance (NFI), Housing Assistance provided by the Federal Emergency Management Agency (FEMA-HA), disaster loan offered by the Small Business Administration (SBA loan), a share of household liquid assets, and Community Development Block Grant Disaster Recovery (CDBG-DR) fund provided by the Department of Housing and Urban Development (HUD). Further, household income determines the amount of rent that it can afford. Community conditions are assessed for each household based on the restoration of specific anchors. ASNA indexes (Nejat, Moradi, & Ghosh 2019) are used to identify the category of community anchors that is important to a recovery decision of each household. Accordingly, households are indexed into three classes for each of which recovery of infrastructure, neighbors, or community assets matters most. Further, among similar anchors, those anchors are important to a household that are located in its perceived neighborhood area (Moradi, Nejat, Hu, & Ghosh 2020).
Addressing Barriers to Primary Care Access for Latinos in the U.S.: An Agent-Based Model
S.R. Aurora (a.k.a. Mai P. Trinh) Hyunsung Oh | Published Tuesday, August 16, 2022Disparities in access to primary health care have led to health disadvantages among Latinos and other non-White racial groups. To better identify and understand which policies are most likely to improve health care for Latinos, we examined differences in access to primary care between Latinos with proficient English language skills and Latinos with limited English proficiency (LEP) and estimated the extent of access to primary care providers (PCPs) among Latinos in the U.S.
Cultural transmission in structured populations
Luke Premo | Published Wednesday, November 13, 2024This structured population model is built to address how migration (or intergroup cultural transmission), copying error, and time-averaging affect regional variation in a single selectively neutral discrete cultural trait under different mechanisms of cultural transmission. The model allows one to quantify cultural differentiation between groups within a structured population (at equilibrium) as well as between regional assemblages of time-averaged archaeological material at two different temporal scales (1,000 and 10,000 ticks). The archaeological assemblages begin to accumulate only after a “burn-in” period of 10,000 ticks. The model includes two different representations of copying error: the infinite variants model of copying error and the finite model of copying error. The model also allows the user to set the variant ceiling value for the trait in the case of the finite model of copying error.
Schelling Model of the City of Salzburg
Andreas Schlagbauer | Published Monday, December 05, 2022The purpose of the model is to better understand, how different factors for human residential choices affect the city’s segregation pattern. Therefore, a Schelling (1971) model was extended to include ethnicity, income, and affordability and applied to the city of Salzburg. So far, only a few studies have tried to explore the effect of multiple factors on the residential pattern (Sahasranaman & Jensen, 2016, 2018; Yin, 2009). Thereby, models using multiple factors can produce more realistic results (Benenson et al., 2002). This model and the corresponding thesis aim to fill that gap.
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
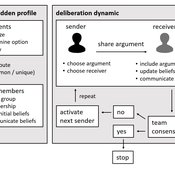
Agent-based model of team decision-making in hidden profile situations
Jonas Stein Andreas Flache Vincenz Frey | Published Thursday, April 20, 2023 | Last modified Friday, November 17, 2023The model presented here is extensively described in the paper ‘Talk less to strangers: How homophily can improve collective decision-making in diverse teams’ (forthcoming at JASSS). A full replication package reproducing all results presented in the paper is accessible at https://osf.io/76hfm/.
Narrative documentation includes a detailed description of the model, including a schematic figure and an extensive representation of the model in pseudocode.
The model develops a formal representation of a diverse work team facing a decision problem as implemented in the experimental setup of the hidden-profile paradigm. We implement a setup where a group seeks to identify the best out of a set of possible decision options. Individuals are equipped with different pieces of information that need to be combined to identify the best option. To this end, we assume a team of N agents. Each agent belongs to one of M groups where each group consists of agents who share a common identity.
The virtual teams in our model face a decision problem, in that the best option out of a set of J discrete options needs to be identified. Every team member forms her own belief about which decision option is best but is open to influence by other team members. Influence is implemented as a sequence of communication events. Agents choose an interaction partner according to homophily h and take turns in sharing an argument with an interaction partner. Every time an argument is emitted, the recipient updates her beliefs and tells her team what option she currently believes to be best. This influence process continues until all agents prefer the same option. This option is the team’s decision.
Displaying 10 of 112 results for "Yunnan University" clear search