About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 37 results replication clear search
Peer reviewed Torsten Hägerstrand’s Spatial Innovation Diffusion Model
Sean Bergin | Published Friday, September 14, 2012 | Last modified Saturday, April 27, 2013This model is a replication of Torsten Hägerstrand’s 1965 model–one of the earliest known calibrated and validated simulations with implicit “agent based” methodology.
Peer reviewed Artificial Anasazi
Marco Janssen | Published Tuesday, September 07, 2010 | Last modified Saturday, April 27, 2013Replication of the well known Artificial Anasazi model that simulates the population dynamics between 800 and 1350 in the Long House Valley in Arizona.
![No submitted images [175x175]](data:image/svg+xml;charset=UTF-8,%3Csvg%20width%3D%22175%22%20height%3D%22175%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%20viewBox%3D%220%200%20175%20175%22%20preserveAspectRatio%3D%22none%22%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%23holder_195e205b623%20text%20%7B%20fill%3A%23AAAAAA%3Bfont-weight%3Abold%3Bfont-family%3AArial%2C%20Helvetica%2C%20Open%20Sans%2C%20sans-serif%2C%20monospace%3Bfont-size%3A10pt%20%7D%20%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cg%20id%3D%22holder_195e205b623%22%3E%3Crect%20width%3D%22175%22%20height%3D%22175%22%20fill%3D%22%23EEEEEE%22%3E%3C%2Frect%3E%3Cg%3E%3Ctext%20x%3D%2217.5%22%20y%3D%2292%22%3ENo%20submitted%20images%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
Peer reviewed An extended replication of Abelson's and Bernstein's community referendum simulation
Klaus G. Troitzsch | Published Friday, October 25, 2019 | Last modified Friday, August 25, 2023This is an extended replication of Abelson’s and Bernstein’s early computer simulation model of community referendum controversies which was originally published in 1963 and often cited, but seldom analysed in detail. This replication is in NetLogo 6.3.0, accompanied with an ODD+D protocol and class and sequence diagrams.
This replication replaces the original scales for attitude position and interest in the referendum issue which were distributed between 0 and 1 with values that are initialised according to a normal distribution with mean 0 and variance 1 to make simulation results easier compatible with scales derived from empirical data collected in surveys such as the European Value Study which often are derived via factor analysis or principal component analysis from the answers to sets of questions.
Another difference is that this model is not only run for Abelson’s and Bernstein’s ten week referendum campaign but for an arbitrary time in order that one can find out whether the distributions of attitude position and interest in the (still one-dimensional) issue stabilise in the long run.

Peer reviewed SequiaBasalto model
Diego J. Soler-Navarro Alicia Tenza Peral Francisco Dieguez Cameroni Pierre Bommel Marco Janssen Irene Perez Ibarra | Published Friday, May 26, 2023This is a replication of the SequiaBasalto model, originally built in Cormas by Dieguez Cameroni et al. (2012, 2014, Bommel et al. 2014 and Morales et al. 2015). The model aimed to test various adaptations of livestock producers to the drought phenomenon provoked by climate change. For that purpose, it simulates the behavior of one livestock farm in the Basaltic Region of Uruguay. The model incorporates the price of livestock, fodder and paddocks, as well as the growth of grass as a function of climate and seasons (environmental submodel), the life cycle of animals feeding on the pasture (livestock submodel), and the different strategies used by farmers to manage their livestock (management submodel). The purpose of the model is to analyze to what degree the common management practices used by farmers (i.e., proactive and reactive) to cope with seasonal and interannual climate variations allow to maintain a sustainable livestock production without depleting the natural resources (i.e., pasture). Here, we replicate the environmental and livestock submodel using NetLogo.
One year is 368 days. Seasons change every 92 days. Each day begins with the growth of grass as a function of climate and season. This is followed by updating the live weight of cows according to the grass height of their patch, and grass consumption, which is determined based on the updated live weight. After consumption, cows grow and reproduce, and a new grass height is calculated. Cows then move to the patch with less cows and with the highest grass height. This updated grass height value will be the initial grass height for the next day.
![No submitted images [175x175]](data:image/svg+xml;charset=UTF-8,%3Csvg%20width%3D%22175%22%20height%3D%22175%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%20viewBox%3D%220%200%20175%20175%22%20preserveAspectRatio%3D%22none%22%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%23holder_195e205b626%20text%20%7B%20fill%3A%23AAAAAA%3Bfont-weight%3Abold%3Bfont-family%3AArial%2C%20Helvetica%2C%20Open%20Sans%2C%20sans-serif%2C%20monospace%3Bfont-size%3A10pt%20%7D%20%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cg%20id%3D%22holder_195e205b626%22%3E%3Crect%20width%3D%22175%22%20height%3D%22175%22%20fill%3D%22%23EEEEEE%22%3E%3C%2Frect%3E%3Cg%3E%3Ctext%20x%3D%2217.5%22%20y%3D%2292%22%3ENo%20submitted%20images%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
Peer reviewed Gender desegregation in German high schools
Klaus G. Troitzsch | Published Tuesday, February 05, 2019 | Last modified Sunday, November 08, 2020The study goes back to a model created in the 1990s which successfully tried to replicate the changes of the percentages of female teachers among the teaching staff in high schools (“Gymnasien”) in the German federal state of Rheinland-Pfalz. The current version allows for additional validation and calibration of the model and is accompanied with the empirical data against which the model is tested and with an analysis program especially designed to perform the analyses in the most recent journal article.
Peer reviewed Pumpa irrigation model
Irene Perez Ibarra Marco Janssen | Published Wednesday, January 09, 2013 | Last modified Saturday, April 27, 2013This is a replication of the Pumpa model that simulates the Pumpa Irrigation System in Nepal (Cifdaloz et al., 2010).
Peer reviewed PPHPC - Predator-Prey for High-Performance Computing
Nuno Fachada | Published Saturday, August 08, 2015 | Last modified Wednesday, November 25, 2015PPHPC is a conceptual model for studying and evaluating implementation strategies for spatial agent-based models (SABMs). It is a realization of a predator-prey dynamic system, and captures important SABMs characteristics.
Peer reviewed A Neutral Model of Stone Raw Material Procurement
Marco Janssen Simen Oestmo | Published Tuesday, October 01, 2013A simple model of random encounters of materials that produces distributions as found in the archaeological record.
Agent-Based Model of Transhumant Decision-Making Processes in Senegal
Cheick Amed Diloma Gabriel TRAORE Etienne DELAY Djibril Diop Alassane Bah | Published Wednesday, July 03, 2024Sahelian transhumance is a type of socio-economic and environmental pastoral mobility. It involves the movement of herds from their terroir of origin (i.e., their original pastures) to one or more host terroirs, followed by a return to the terroir of origin. According to certain pastoralists, the mobility of herds is planned to prevent environmental degradation, given the continuous dependence of these herds on their environment. However, these herds emit Greenhouse Gases (GHGs) in the spaces they traverse. Given that GHGs contribute to global warming, our long-term objective is to quantify the GHGs emitted by Sahelian herds. The determination of these herds’ GHG emissions requires: (1) the artificial replication of the transhumance, and (2) precise knowledge of the space used during their transhumance.
This article presents the design of an artificial replication of the transhumance through an agent-based model named MSTRANS. MSTRANS determines the space used by transhumant herds, based on the decision-making process of Sahelian transhumants.
MSTRANS integrates a constrained multi-objective optimization problem and algorithms into an agent-based model. The constrained multi-objective optimization problem encapsulates the rationality and adaptability of pastoral strategies. Interactions between a transhumant and its socio-economic network are modeled using algorithms, diffusion processes, and within the multi-objective optimization problem. The dynamics of pastoral resources are formalized at various spatio-temporal scales using equations that are integrated into the algorithms.
The results of MSTRANS are validated using GPS data collected from transhumant herds in Senegal. MSTRANS results highlight the relevance of integrated models and constrained multi-objective optimization for modeling and monitoring the movements of transhumant herds in the Sahel. Now specialists in calculating greenhouse gas emissions have a reproducible and reusable tool for determining the space occupied by transhumant herds in a Sahelian country. In addition, decision-makers, pastoralists, veterinarians and traders have a reproducible and reusable tool to help them make environmental and socio-economic decisions.
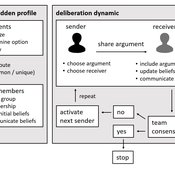
Agent-based model of team decision-making in hidden profile situations
Jonas Stein Andreas Flache Vincenz Frey | Published Thursday, April 20, 2023 | Last modified Friday, November 17, 2023The model presented here is extensively described in the paper ‘Talk less to strangers: How homophily can improve collective decision-making in diverse teams’ (forthcoming at JASSS). A full replication package reproducing all results presented in the paper is accessible at https://osf.io/76hfm/.
Narrative documentation includes a detailed description of the model, including a schematic figure and an extensive representation of the model in pseudocode.
The model develops a formal representation of a diverse work team facing a decision problem as implemented in the experimental setup of the hidden-profile paradigm. We implement a setup where a group seeks to identify the best out of a set of possible decision options. Individuals are equipped with different pieces of information that need to be combined to identify the best option. To this end, we assume a team of N agents. Each agent belongs to one of M groups where each group consists of agents who share a common identity.
The virtual teams in our model face a decision problem, in that the best option out of a set of J discrete options needs to be identified. Every team member forms her own belief about which decision option is best but is open to influence by other team members. Influence is implemented as a sequence of communication events. Agents choose an interaction partner according to homophily h and take turns in sharing an argument with an interaction partner. Every time an argument is emitted, the recipient updates her beliefs and tells her team what option she currently believes to be best. This influence process continues until all agents prefer the same option. This option is the team’s decision.
Displaying 10 of 37 results replication clear search