About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 50 results for "Gil Gambash" clear search

Peer reviewed Agent-based model to simulate equilibria and regime shifts emerged in lake ecosystems
no contributors listed | Published Tuesday, January 25, 2022(An empty output folder named “NETLOGOexperiment” in the same location with the LAKEOBS_MIX.nlogo file is required before the model can be run properly)
The model is motivated by regime shifts (i.e. abrupt and persistent transition) revealed in the previous paleoecological study of Taibai Lake. The aim of this model is to improve a general understanding of the mechanism of emergent nonlinear shifts in complex systems. Prelimnary calibration and validation is done against survey data in MLYB lakes. Dynamic population changes of function groups can be simulated and observed on the Netlogo interface.
Main functional groups in lake ecosystems were modelled as super-individuals in a space where they interact with each other. They are phytoplankton, zooplankton, submerged macrophyte, planktivorous fish, herbivorous fish and piscivorous fish. The relationships between these functional groups include predation (e.g. zooplankton-phytoplankton), competition (phytoplankton-macrophyte) and protection (macrophyte-zooplankton). Each individual has properties in size, mass, energy, and age as physiological variables and reproduce or die according to predefined criteria. A system dynamic model was integrated to simulate external drivers.
Set biological and environmental parameters using the green sliders first. If the data of simulation are to be logged, set “Logdata” as true and input the name of the file you want the spreadsheet(.csv) to be called. You will need create an empty folder called “NETLOGOexperiment” in the same level and location with the LAKEOBS_MIX.nlogo file. Press “setup” to initialise the system and “go” to start life cycles.
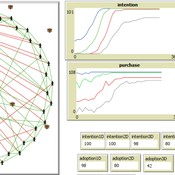
Diffusion of goods with multiple characteristics and price premiums
Pedro López Merino | Published Friday, February 18, 2022An agent-based model for the diffusion of innovations with multiple characteristics and price-premiums
Peer reviewed The Archaeological Sampling Experimental Laboratory (tASEL)
Isaac Ullah | Published Friday, March 11, 2022 | Last modified Wednesday, June 01, 2022The Archaeological Sampling Experimental Laboratory (tASEL) is an interactive tool for setting up and conducting experiments about sampling strategies for archaeological excavation, survey, and prospection.
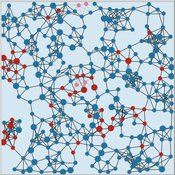
Peer reviewed Virus Transmission with Super-spreaders
J M Applegate | Published Saturday, September 11, 2021A curious aspect of the Covid-19 pandemic is the clustering of outbreaks. Evidence suggests that 80\% of people who contract the virus are infected by only 19% of infected individuals, and that the majority of infected individuals faile to infect another person. Thus, the dispersion of a contagion, $k$, may be of more use in understanding the spread of Covid-19 than the reproduction number, R0.
The Virus Transmission with Super-spreaders model, written in NetLogo, is an adaptation of the canonical Virus Transmission on a Network model and allows the exploration of various mitigation protocols such as testing and quarantines with both homogenous transmission and heterogenous transmission.
The model consists of a population of individuals arranged in a network, where both population and network degree are tunable. At the start of the simulation, a subset of the population is initially infected. As the model runs, infected individuals will infect neighboring susceptible individuals according to either homogenous or heterogenous transmission, where heterogenous transmission models super-spreaders. In this case, k is described as the percentage of super-spreaders in the population and the differing transmission rates for super-spreaders and non super-spreaders. Infected individuals either recover, at which point they become resistant to infection, or die. Testing regimes cause discovered infected individuals to quarantine for a period of time.
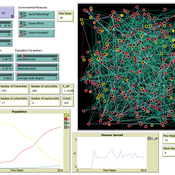
The Effect of Different Governmental Pandemic Control Measures on the Spread of a Virus Disease
Chiara Letter | Published Wednesday, January 26, 2022In this model, the spread of a virus disease in a network consisting of school pupils, employed, and umemployed people is simulated. The special feature in this model is the distinction between different types of links: family-, friends-, school-, or work-links. In this way, different governmental measures can be implemented in order to decelerate or stop the transmission.
Peer reviewed TRANSOPE: a multi-agent model to simulate outsourcing networks in road freight transport.
Aitor Salas-Peña Blanca Rosa Cases Gutiérrez | Published Friday, October 21, 2022A road freight transport (RFT) operation involves the participation of several types of companies in its execution. The TRANSOPE model simulates the subcontracting process between 3 types of companies: Freight Forwarders (FF), Transport Companies (TC) and self-employed carriers (CA). These companies (agents) form transport outsourcing chains (TOCs) by making decisions based on supplier selection criteria and transaction acceptance criteria. Through their participation in TOCs, companies are able to learn and exchange information, so that knowledge becomes another important factor in new collaborations. The model can replicate multiple subcontracting situations at a local and regional geographic level.
The succession of n operations over d days provides two types of results: 1) Social Complex Networks, and 2) Spatial knowledge accumulation environments. The combination of these results is used to identify the emergence of new logistics clusters. The types of actors involved as well as the variables and parameters used have their justification in a survey of transport experts and in the existing literature on the subject.
As a result of a preferential selection process, the distribution of activity among agents shows to be highly uneven. The cumulative network resulting from the self-organisation of the system suggests a structure similar to scale-free networks (Albert & Barabási, 2001). In this sense, new agents join the network according to the needs of the market. Similarly, the network of preferential relationships persists over time. Here, knowledge transfer plays a key role in the assignment of central connector roles, whose participation in the outsourcing network is even more decisive in situations of scarcity of transport contracts.
Exploring Urban Shrinkage
Andrew Crooks | Published Thursday, March 19, 2020While the world’s total urban population continues to grow, this growth is not equal. Some cities are declining, resulting in urban shrinkage which is now a global phenomenon. Many problems emerge due to urban shrinkage including population loss, economic depression, vacant properties and the contraction of housing markets. To explore this issue, this paper presents an agent-based model stylized on spatially explicit data of Detroit Tri-county area, an area witnessing urban shrinkage. Specifically, the model examines how micro-level housing trades impact urban shrinkage by capturing interactions between sellers and buyers within different sub-housing markets. The stylized model results highlight not only how we can simulate housing transactions but the aggregate market conditions relating to urban shrinkage (i.e., the contraction of housing markets). To this end, the paper demonstrates the potential of simulation to explore urban shrinkage and potentially offers a means to test polices to alleviate this issue.
OMOLAND-CA: An Agent-Based Modeling of Rural Households’ Adaptation to Climate Change
Atesmachew Hailegiorgis Claudio Cioffi-Revilla Andrew Crooks | Published Tuesday, July 25, 2017 | Last modified Tuesday, July 10, 2018The purpose of the OMOLAND-CA is to investigate the adaptive capacity of rural households in the South Omo zone of Ethiopia with respect to variation in climate, socioeconomic factors, and land-use at the local level.

Introducing two extensions of Schelling's segregation model
Andreas Flache Carlos A. de Matos Fernandes | Published Monday, January 25, 2021Schelling famously proposed an extremely simple but highly illustrative social mechanism to understand how strong ethnic segregation could arise in a world where individuals do not necessarily want it. Schelling’s simple computational model is the starting point for our extensions in which we build upon Wilensky’s original NetLogo implementation of this model. Our two NetLogo models can be best studied while reading our chapter “Agent-based Computational Models” (Flache and de Matos Fernandes, 2021). In the chapter, we propose 10 best practices to elucidate how agent-based models are a unique method for providing and analyzing formally precise, and empirically plausible mechanistic explanations of puzzling social phenomena, such as segregation, in the social world. Our chapter addresses in particular analytical sociologists who are new to ABMs.
In the first model (SegregationExtended), we build on Wilensky’s implementation of Schelling’s model which is available in NetLogo library (Wilensky, 1997). We considerably extend this model, allowing in particular to include larger neighborhoods and a population with four groups roughly resembling the ethnic composition of a contemporary large U.S. city. Further features added concern the possibility to include random noise, and the addition of a number of new outcome measures tuned to highlight macro-level implications of the segregation dynamics for different groups in the agent society.
In SegregationDiscreteChoice, we further modify the model incorporating in particular three new features: 1) heterogeneous preferences roughly based on empirical research categorizing agents into low, medium, and highly tolerant within each of the ethnic subgroups of the population, 2) we drop global thresholds (%-similar-wanted) and introduce instead a continuous individual-level single-peaked preference function for agents’ ideal neighborhood composition, and 3) we use a discrete choice model according to which agents probabilistically decide whether to move to a vacant spot or stay in the current spot by comparing the attractiveness of both locations based on the individual preference functions.
…
Artificial Long House Valley-Black Mesa
Amy Warren Lisa Sattenspiel | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
Displaying 10 of 50 results for "Gil Gambash" clear search