About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 54 results for "Rahul Goel" clear search
Peer reviewed Gender desegregation in German high schools
Klaus G. Troitzsch | Published Tuesday, February 05, 2019 | Last modified Sunday, November 08, 2020The study goes back to a model created in the 1990s which successfully tried to replicate the changes of the percentages of female teachers among the teaching staff in high schools (“Gymnasien”) in the German federal state of Rheinland-Pfalz. The current version allows for additional validation and calibration of the model and is accompanied with the empirical data against which the model is tested and with an analysis program especially designed to perform the analyses in the most recent journal article.
Local soy value chains in northern Ghana
Tim Verwaart | Published Thursday, August 29, 2019The purpose of the simulation is to evaluate alternative interventions by a value chain development program, aiming to improve rural livelihood and food and nutrition security. In northern Ghana, where distrust between the partners can be a problem in the functioning of value chains, the program supports the incorporation of smallholder farmers in soy clusters or agriculture APEX organization (farmers’ co-operatives) with a fair business environment. The goal is to to include the smallholder farmers in a strong value chain and reduce distrust.
CONSERVAT
Pieter Van Oel | Published Monday, April 13, 2015The CONSERVAT model evaluates the effect of social influence among farmers in the Lake Naivasha basin (Kenya) on the spatiotemporal diffusion pattern of soil conservation effort levels and the resulting reduction in lake sedimentation.
Dental Routine Check-Up
Peyman Shariatpanahi Afshin Jafari | Published Thursday, March 10, 2016 | Last modified Monday, April 08, 2019We develop an agent-based model for collective behavior of routine medical check-ups, and specifically dental visits, in a social network.

Investor-based electricity market model
Oscar Kraan | Published Monday, January 02, 2017 | Last modified Friday, October 12, 2018The model is a representation of a liberalised electricity market designed as an energy-only market and consists of large scale investors and their power generation assets in the electricity market.
ReMoTe-S. Residential Mobility of Tenants in Switzerland: an agent-based model
Anna Pagani Francesco Ballestrazzi Emanuele Massaro Claudia Binder | Published Friday, April 01, 2022ReMoTe-S is an agent-based model of the residential mobility of Swiss tenants. Its goal is to foster a holistic understanding of the reciprocal influence between households and dwellings and thereby inform a sustainable management of the housing stock. The model is based on assumptions derived from empirical research conducted with three housing providers in Switzerland and can be used mainly for two purposes: (i) the exploration of what if scenarios that target a reduction of the housing footprint while accounting for households’ preferences and needs; (ii) knowledge production in the field of residential mobility and more specifically on the role of housing functions as orchestrators of the relocation process.

Foundress dilemma model
Zachary Joseph Shaffer Takao Sasaki Brian Haney Marco Janssen Stephen Pratt Jennifer Fewell | Published Thursday, July 28, 2016A haystack-style model of group selection to capture the essential features of colony foundation for queens of the ant based on observation of the ant Pogonomyrmex californicus.
Cliff Walking with Q-Learning NetLogo Extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
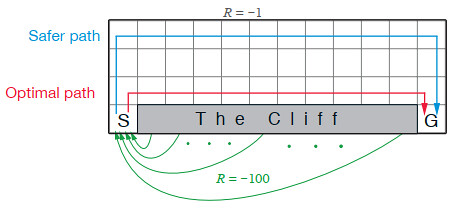
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension
Benchmark for DMASON
Andreu Moreno Vendrell Eduardo César Anna Sikora Josep Jorba Cristina Peralta Quesada | Published Friday, November 22, 2024Agent-based modeling and simulation (ABMS) is a class of computational models for simulating the actions and interactions of autonomous agents with the goal of assessing their effects on a system as a whole. Several frameworks for generating parallel ABMS applications have been developed taking advantage of their common characteristics, but there is a lack of a general benchmark for comparing the performance of generated applications. We propose and design a benchmark that takes into consideration the most common characteristics of this type of applications and includes parameters for influencing their relevant performance aspects. We provide an initial implementation of the benchmark for DMASON parallel ABMS platform, and we use it for comparing the applications generated by these platforms.
Direct versus Connect
Steven Kimbrough | Published Sunday, January 15, 2023This NetLogo model is an implementation of the mostly verbal (and graphic) model in Jarret Walker’s Human Transit: How Clearer Thinking about Public Transit Can Enrich Our Communities and Our Lives (2011). Walker’s discussion is in the chapter “Connections or Complexity?”. See especially figure 12-2, which is on page 151.
In “Connections or Complexity?”, Walker frames the matter as involving a choice between two conflicting goals. The first goal is to minimize connections, the need to make transfers, in a transit system. People naturally prefer direct routes. The second goal is to minimize complexity. Why? Well, read the chapter, but as a general proposition we want to avoid unnecessary complexity with its attendant operating characteristics (confusing route plans in the case of transit) and management and maintenance challenges. With complexity general comes degraded robustness and resilience.
How do we, how can we, choose between these conflicting goals? The grand suggestion here is that we only choose indirectly, implicitly. In the present example of connections versus complexity we model various alternatives and compare them on measures of performance (MoP) other than complexity or connections per se. The suggestion is that connections and complexity are indicators of, heuristics for, other MoPs that are more fundamental, such as cost, robustness, energy use, etc., and it is these that we at bottom care most about. (Alternatively, and not inconsistently, we can view connections and complexity as two of many MoPs, with the larger issue to be resolve in light of many MoPs, including but not limited to complexity and connections.) We employ modeling to get a handle on these MoPs. Typically, there will be several, taking us thus to a multiple criteria decision making (MCDM) situation. That’s the big picture.
Displaying 10 of 54 results for "Rahul Goel" clear search