About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 187 results for "Francisco J Miguel" clear search
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
Artificial Long House Valley-Black Mesa
Lisa Sattenspiel Amy Warren | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
Peer reviewed SIM-VOLATILE: Adoption of emerging circular technologies in the waste-treatment sector
Siavash Farahbakhsh | Published Wednesday, December 14, 2022The SIM-VOLATILE model is a technology adoption model at the population level. The technology, in this model, is called Volatile Fatty Acid Platform (VFAP) and it is in the frame of the circular economy. The technology is considered an emerging technology and it is in the optimization phase. Through the adoption of VFAP, waste-treatment plants will be able to convert organic waste into high-end products rather than focusing on the production of biogas. Moreover, there are three adoption/investment scenarios as the technology enables the production of polyhydroxyalkanoates (PHA), single-cell oils (SCO), and polyunsaturated fatty acids (PUFA). However, due to differences in the processing related to the products, waste-treatment plants need to choose one adoption scenario.
In this simulation, there are several parameters and variables. Agents are heterogeneous waste-treatment plants that face the problem of circular economy technology adoption. Since the technology is emerging, the adoption decision is associated with high risks. In this regard, first, agents evaluate the economic feasibility of the emerging technology for each product (investment scenarios). Second, they will check on the trend of adoption in their social environment (i.e. local pressure for each scenario). Third, they combine these two economic and social assessments with an environmental assessment which is their environmental decision-value (i.e. their status on green technology). This combination gives the agent an overall adaptability fitness value (detailed for each scenario). If this value is above a certain threshold, agents may decide to adopt the emerging technology, which is ultimately depending on their predominant adoption probabilities and market gaps.
BEEHAVE Extension: Varroa mite control within Good Beekeeping Practice in Germany
Volker Grimm Jürgen Groeneveld Isabel Schödl | Published Wednesday, May 25, 2022 | Last modified Monday, November 07, 2022The western honey bee Apis mellifera is the most important pollinator in the world. The biggest threat to managed honey bees is the ectoparasitic mite Varroa destructor and the viruses DWV (Deformed Wing Virus) and APV (Acute Paralysis Virus) it transmits. Untreated honey bee colonies are expected to die within one to three years. This led to the development of strategies for beekeepers to control the Varroa mite in honey bee colonies and ensure the health and survival of their bee colonies, so called Good Beekeeping Practice. The aim of the extension of BEEHAVE was to represent the Good Beekeeping Practice of Varroa control in Germany. The relevant measures within the Varroa control strategies are drone brood removal as a Varroa trap and the treatment of bee colonies with organic acaricides (formic and oxalic acid) to kill the mites. This extension improves BEEHAVE and builds a bridge between beekeepers in practice and in the modelling world. It vastly contributes to the future use of BEEHAVE in beekeeping education in Germany.
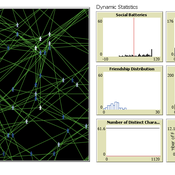
The Friendship Field
Eva Timmer Chrisja van de Kieft | Published Thursday, May 26, 2022 | Last modified Tuesday, August 30, 2022The Friendship Field model aims at modelling friendship formation based on three factors: Extraversion, Resemblance and Status, where social interaction is motivated by the Social Battery. Social Battery is one’s energy and motivation to engage in social contact. Since social contact is crucial for friendship formation, the model included Social Battery to affect social interactions. To our best knowledge, Social Battery is a yet unintroduced concept in research while it is a dynamic factor influencing the social interaction besides one’s characteristics. Extraverts’ Social Batteries charge while interacting and exhaust while being alone. Introverts’ Social Batteries charge while being alone and exhaust while interacting. The aim of the model is to illustrate the concept of Social Battery. Moreover, the Friendship Field shows patterns regarding Extraversion, Resemblance and Status including the mere-exposure effect and friendship by similarity. For the implementation of Status, Kemper’s status-power theory is used. The concept of Social Battery is also linked to Kemper’s theory on the organism as reference group. By running the model for a year (3 interactions moments per day), the friendship dynamics over time can be studied.
We presented the model at the Social Simulation Conference 2022.
Identity and meat eating behaviour
Jiaqi Ge | Published Thursday, September 29, 2022Using data from the British Social Attitude Survey, we develop an agent-based model to study the effect of social influence on the spread of meat-eating behaviour in the British population.

MCA-SdA (ABM of mining-community-aquifer interactions in Salar de Atacama, Chile)
Wenjuan Liu | Published Tuesday, December 01, 2020 | Last modified Thursday, November 04, 2021This model represnts an unique human-aquifer interactions model for the Li-extraction in Salar de Atacama, Chile. It describes the local actors’ experience of mining-induced changes in the socio-ecological system, especially on groundwater changes and social stressors. Social interactions are designed specifically according to a long-term local fieldwork by Babidge et al. (2019, 2020). The groundwater system builds on the FlowLogo model by Castilla-Rho et al. (2015), which was then parameterized and calibrated with local hydrogeological inputs in Salar de Atacama, Chile. The social system of the ABM is defined and customozied based on empirical studies to reflect three major stressors: drought stress, population stress, and mining stress. The model reports evolution of groundwater changes and associated social stress dynamics within the modeled time frame.
A formalized implementation of Halstead and O’Shea’s Bad Year Economics. The agent population uses one of four resilience strategies in an attempt to cope with a dynamic environment of stresses and shocks.
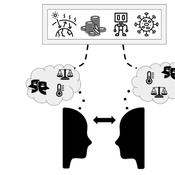
Peer reviewed Dynamic Value-based Cognitive Architectures
Bart de Bruin | Published Tuesday, November 30, 2021The intention of this model is to create an universal basis on how to model change in value prioritizations within social simulation. This model illustrates the designing of heterogeneous populations within agent-based social simulations by equipping agents with Dynamic Value-based Cognitive Architectures (DVCA-model). The DVCA-model uses the psychological theories on values by Schwartz (2012) and character traits by McCrae and Costa (2008) to create an unique trait- and value prioritization system for each individual. Furthermore, the DVCA-model simulates the impact of both social persuasion and life-events (e.g. information, experience) on the value systems of individuals by introducing the innovative concept of perception thermometers. Perception thermometers, controlled by the character traits, operate as buffers between the internal value prioritizations of agents and their external interactions. By introducing the concept of perception thermometers, the DVCA-model allows to study the dynamics of individual value prioritizations under a variety of internal and external perturbations over extensive time periods. Possible applications are the use of the DVCA-model within artificial sociality, opinion dynamics, social learning modelling, behavior selection algorithms and social-economic modelling.
This is the R code of the mathematical model that includes the decision making formulations for artificial agents. Plus, the code for graphical output is also added to the original code.
Displaying 10 of 187 results for "Francisco J Miguel" clear search