About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 1203 results

Animal territory formation (Reusable Building Block RBB)
Volker Grimm Stephanie Kramer-Schadt Robert Zakrzewski | Published Sunday, November 12, 2023This is a generic sub-model of animal territory formation. It is meant to be a reusable building block, but not in the plug-and-play sense, as amendments are likely to be needed depending on the species and region. The sub-model comprises a grid of cells, reprenting the landscape. Each cell has a “quality” value, which quantifies the amount of resources provided for a territory owner, for example a tiger. “Quality” could be prey density, shelter, or just space. Animals are located randomly in the landscape and add grid cells to their intial cell until the sum of the quality of all their cells meets their needs. If a potential new cell to be added is owned by another animal, competition takes place. The quality values are static, and the model does not include demography, i.e. mortality, mating, reproduction. Also, movement within a territory is not represented.
An agent-based model of cultural change for a low-carbon transition
Daniel Torren-Peraire | Published Friday, November 10, 2023An ABM of changes in individuals’ lifestyles which considers their
evolving behavioural choices. Individuals have a set of environmental behavioural traits that spread through a fixed Watts–Strogatz graph via social interactions with their neighbours. These exchanges are mediated by transmission biases informing from whom an individual learns and
how much attention is paid. The influence of individuals on each other is a function of their similarity in environmental identity, where we represent environmental identity computationally by aggregating past agent attitudes towards multiple environmentally related behaviours. To perform a behaviour, agents must both have
a sufficiently positive attitude toward a behaviour and overcome a corresponding threshold. This threshold
structure, where the desire to perform a behaviour does not equal its enactment, allows for a lack of coherence
between attitudes and actual emissions. This leads to a disconnect between what people believe and what
…

Peer reviewed COMMONSIM: Simulating the utopia of COMMONISM
Lena Gerdes Manuel Scholz-Wäckerle Ernest Aigner Stefan Meretz Jens Schröter Hanno Pahl Annette Schlemm Simon Sutterlütti | Published Sunday, November 05, 2023This research article presents an agent-based simulation hereinafter called COMMONSIM. It builds on COMMONISM, i.e. a large-scale commons-based vision for a utopian society. In this society, production and distribution of means are not coordinated via markets, exchange, and money, or a central polity, but via bottom-up signalling and polycentric networks, i.e. ex-ante coordination via needs. Heterogeneous agents care for each other in life groups and produce in different groups care, environmental as well as intermediate and final means to satisfy sensual-vital needs. Productive needs decide on the magnitude of activity in groups for a common interest, e.g. the production of means in a multi-sectoral artificial economy. Agents share cultural traits identified by different behaviour: a propensity for egoism, leisure, environmentalism, and productivity. The narrative of this utopian society follows principles of critical psychology and sociology, complexity and evolution, the theory of commons, and critical political economy. The article presents the utopia and an agent-based study of it, with emphasis on culture-dependent allocation mechanisms and their social and economic implications for agents and groups.
Peer reviewed Yards
srailsback Emily Minor Soraida Garcia Philip Johnson | Published Thursday, November 02, 2023This is a model of plant communities in urban and suburban residential neighborhoods. These plant communities are of interest because they provide many benefits to human residents and also provide habitat for wildlife such as birds and pollinators. The model was designed to explore the social factors that create spatial patterns in biodiversity in yards and gardens. In particular, the model was originally developed to determine whether mimicry behaviors–-or neighbors copying each other’s yard design–-could produce observed spatial patterns in vegetation. Plant nurseries and socio-economic constraints were also added to the model as other potential sources of spatial patterns in plant communities.
The idea for the model was inspired by empirical patterns of spatial autocorrelation that have been observed in yard vegetation in Chicago, Illinois (USA), and other cities, where yards that are closer together are more similar than yards that are farther apart. The idea is further supported by literature that shows that people want their yards to fit into their neighborhood. Currently, the yard attribute of interest is the number of plant species, or species richness. Residents compare the richness of their yards to the richness of their neighbors’ yards. If a resident’s yard is too different from their neighbors, the resident will be unhappy and change their yard to make it more similar.
The model outputs information about the diversity and identity of plant species in each yard. This can be analyzed to look for spatial autocorrelation patterns in yard diversity and to explore relationships between mimicry behaviors, yard diversity, and larger scale diversity.
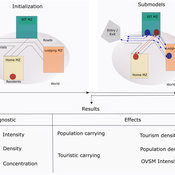
Peer reviewed ABM Overtourism Santa Marta
Janwar Moreno | Published Monday, October 23, 2023This model presents the simulation model of a city in the context of overtourism. The study area is the city of Santa Marta in Colombia. The purpose is to illustrate the spatial and temporal distribution of population and tourists in the city. The simulation analyzes emerging patterns that result from the interaction between critical components in the touristic urban system: residents, urban space, touristic sites, and tourists. The model is an Agent-Based Model (ABM) with the GAMA software. Also, it used public input data from statistical centers, geographical information systems, tourist websites, reports, and academic articles. The ABM includes assessing some measures used to address overtourism. This is a field of research with a low level of analysis for destinations with overtourism, but the ABM model allows it. The results indicate that the city has a high risk of overtourism, with spatial and temporal differences in the population distribution, and it illustrates the effects of two management measures of the phenomenon on different scales. Another interesting result is the proposed tourism intensity indicator (OVsm), taking into account that the tourism intensity indicators used by the literature on overtourism have an overestimation of tourism pressures.

Peer reviewed HUMLAND: HUMan impact on LANDscapes agent-based model
Fulco Scherjon Anastasia Nikulina Anhelina Zapolska Maria Antonia Serge Marco Davoli Dave van Wees Katharine MacDonald | Published Monday, October 16, 2023The HUMan impact on LANDscapes (HUMLAND) model has been developed to track and quantify the intensity of different impacts on landscapes at the continental level. This agent-based model focuses on determining the most influential factors in the transformation of interglacial vegetation with a specific emphasis on burning organized by hunter-gatherers. HUMLAND integrates various spatial datasets as input and target for the agent-based model results. Additionally, the simulation incorporates recently obtained continental-scale estimations of fire return intervals and the speed of vegetation regrowth. The obtained results include maps of possible scenarios of modified landscapes in the past and quantification of the impact of each agent, including climate, humans, megafauna, and natural fires.
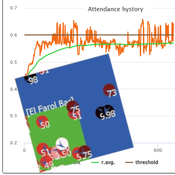
Peer reviewed Flibs’NFarol: Self-Organized Efficiency and Fairness Emergence in an Evolutive Game
Cosimo Leuci | Published Thursday, October 12, 2023According to the philosopher of science K. Popper “All life is problem solving”. Genetic algorithms aim to leverage Darwinian selection, a fundamental mechanism of biological evolution, so as to tackle various engineering challenges.
Flibs’NFarol is an Agent Based Model that embodies a genetic algorithm applied to the inherently ill-defined “El Farol Bar” problem. Within this context, a group of agents operates under bounded rationality conditions, giving rise to processes of self-organization involving, in the first place, efficiency in the exploitation of available resources. Over time, the attention of scholars has shifted to equity in resource distribution, as well. Nowadays, the problem is recognized as paradigmatic within studies of complex evolutionary systems.
Flibs’NFarol provides a platform to explore and evaluate factors influencing self-organized efficiency and fairness. The model represents agents as finite automata, known as “flibs,” and offers flexibility in modifying the number of internal flibs states, which directly affects their behaviour patterns and, ultimately, the diversity within populations and the complexity of the system.

Peer reviewed A Bayesian Nash Equilibrium (BNE)-informed ABM for pedestrian evacuation in different constricted spaces
Jiaqi Ge Yiyu Wang Alexis Comber | Published Wednesday, October 11, 2023This BNE-informed ABM ultimately aims to provide a more realistic description of complicated pedestrian behaviours especially in high-density and life-threatening situations. Bayesian Nash Equilibrium (BNE) was adopted to reproduce interactive decision-making process among rational and game-playing agents. The implementations of 3 behavioural models, which are Shortest Route (SR) model, Random Follow (RF) model, and BNE model, make it possible to simulate emergent patterns of pedestrian behaviours (e.g. herding and self-organised queuing behaviours, etc.) in emergency situations.
According to the common features of previous mass trampling accidents, a series of simulation experiments were performed in space with 3 types of barriers, which are Horizontal Corridors, Vertical Corridors, and Random Squares, standing for corridors, bottlenecks and intersections respectively, to investigate emergent behaviours of evacuees in varied constricted spatial environments. The output of this ABM has been available at https://data.mendeley.com/datasets/9v4byyvgxh/1.
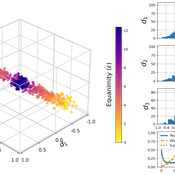
Weighted Balance Model of Issue Alignment and Polarization
David Garcia Simon Schweighofer | Published Sunday, October 08, 2023This model is pertinent to our JASSS publication “Raising the Spectrum of Polarization: Generating Issue Alignment with a Weighted Balance Opinion Dynamics Model”. It shows how, based on the mechanisms of our Weighted Balance Theory (a development of Fritz Heider’s Cognitive Balance Theory), agents can self-organize in a multi-dimensional opinion space and form an emergent ideological spectrum. The degree of issue alignment and polarization realized by the model depends mainly on the agent-specific ‘equanimity parameter’ epsilon.
Controlling the misinformation diffusion in social media by the effect of different classes of agents
Ali Khodabandeh Yalabadi | Published Thursday, October 05, 2023An agent-based framework to simulate the diffusion process of a piece of misinformation according to the SBFC model in which the fake news and its debunking compete in a social network. Considering new classes of agents, this model is closer to reality and proposed different strategies how to mitigate and control misinformation.
Displaying 10 of 1203 results