Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1225 results for "Ian M Hamilton" clear search
Peer reviewed lgm_ecodynamics
Colin Wren | Published Monday, April 22, 2019This is a modification of a model published previous by Barton and Riel-Salvatore (2012). In this model, we simulate six regional populations within Last Glacial Maximum western Europe. Agents interact through reproduction and genetic markers attached to each of six regions mix through subsequent generations as a way to track population dynamics, mobility, and gene flow. In addition, the landscape is heterogeneous and affects agent mobility and, under certain scenarios, their odds of survival.
Peer reviewed Agent-Based Insight into Eco-Choices: Simulating the Fast Fashion Shift
Daria Soboleva Angel Sánchez | Published Wednesday, August 07, 2024 | Last modified Wednesday, June 11, 2025The present model was created and used for the study titled ``Agent-Based Insight into Eco-Choices: Simulating the Fast Fashion Shift.” The model is implemented in the multi-agent programmable environment NetLogo 6.3.0. The model is designed to simulate the behavior and decision-making processes of individuals (agents) in a social network. It focuses on how agents interact with their peers, social media, and government campaigns, specifically regarding their likelihood to purchase fast fashion.
Seasonal Social Networks and Learning Opportunities Under Unbiased Cultural Transmission
Adam Rorabaugh | Published Monday, May 18, 2015This agent-based model examines the impact of seasonal aggregation, dispersion, and learning opportunities on the richness and evenness of artifact styles under random social learning (unbiased transmission).
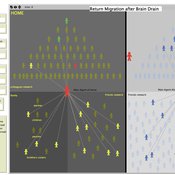
RETURN MIGRATION AFTER BRAIN DRAIN: A SIMULATION APPROACH
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Friday, June 21, 2013This model, realized on the NetLogo platform, compares utility levels at home and abroad to simulate agents’ migration and their eventual return. Our model is based on two fundamental individual features, i.e. risk aversion and initial expectation, which characterize the dynamics of different agents according to the evolution of their social contacts.
Structure of Scientific Revolutions
Rogier De Langhe | Published Friday, September 02, 2016 | Last modified Tuesday, December 04, 2018An agent-based model of Thomas Kuhn’s Structure of Scientific Revolutions
ABM thesis
Lucas Sage | Published Friday, May 06, 2022Netlogo model used to produce the results in my doctoral thesis
Survival analysis and Population viability analysis of the Northern Bald Ibis
Stephanie Kramer-Schadt Cédric Scherer Viktoriia Radchuk Sinah Drenske Corinna Esterer Ingo Kowarik Johannes Fritz | Published Thursday, August 04, 2022This is the full repository to run the survival analysis (in R) and run the population viability model and its analysis (NetLogo + R) of the Northern Bald Ibis (NBI) presented in the study
On the road to self-sustainability: Reintroduced migratory European Northern Bald Ibises (Geronticus eremita) still need management interventions for population viability
by Sinah Drenske, Viktoriia Radchuk, Cédric Scherer, Corinna Esterer, Ingo Kowarik, Johannes Fritz, Stephanie Kramer-Schadt
…
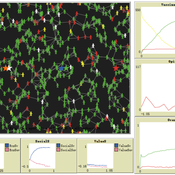
Fear-based COVID model
Teng Li | Published Friday, December 22, 2023This model simulates the opinion dynamics of COVID-19 vaccination to examine especially how fears and cognitive bias contribute to the opinion polarisation and vaccination rate. In studying the opinion dynamics of COVID-19 vaccination, this model refers to the HUMAT framework (Antosz et al, 2019). Many psychological and social processes are included in the model, such as dynamical decision-making processes of information exchange and fear formation, satisfaction evaluation, preferred decision selection and dissonance reduction.
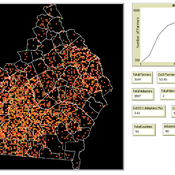
Modelling Farmers’ Adoption Potential to New Bioenergy Crops
Andrew Crooks | Published Tuesday, November 29, 2022A model that representa farmers potential to adopt bio-fuels in Georgia
Model of a Socioterritorial complex system - The Southern Rural Territory of Sergipe
Marcos Aurélio Santos da Silva | Published Friday, May 18, 2018The model represents a set of social actors engaged into a collegiate (composed of representants of civil society and public sector) to manage the Southern Rural Territory of Sergipe (SRTS), created by two territorial public policies, the National Program for the Sustainable Development of Rural Territories (PRONAT) and the Program Territories of Citizenship (PTC) which aim at balancing power relations between social actors of Rural Territories. The main gola of these public policies is to empower the civil society engaged in the territory to enable them to negotiate with the traditional power (mainly majors). It was designed two models of the SRTS, one that represents the situation in 2012, and other that represents the social interdependencies in 2017. For each period it is possible to measure the capability and power of each modeled social actor and see whether it is observed the empowerment of the civil society or not.
Displaying 10 of 1225 results for "Ian M Hamilton" clear search