About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 92 results empirical clear search

Peer reviewed Descriptive Norm and Fraud Dynamics
Alexandra Eckert Matthias Meyer Christian Stindt | Published Tuesday, January 07, 2025The “Descriptive Norm and Fraud Dynamics” model demonstrates how fraudulent behavior can either proliferate or be contained within non-hierarchical organizations, such as peer networks, through social influence taking the form of a descriptive norm. This model expands on the fraud triangle theory, which posits that an individual must concurrently possess a financial motive, perceive an opportunity, and hold a pro-fraud attitude to engage in fraudulent activities (red agent). In the absence of any of these elements, the individual will act honestly (green agent).
The model explores variations in a descriptive norm mechanism, ranging from local distorted knowledge to global perfect knowledge. In the case of local distorted knowledge, agents primarily rely on information from their first-degree colleagues. This knowledge is often distorted because agents are slow to update their empirical expectations, which are only partially revised after one-to-one interactions. On the other end of the spectrum, local perfect knowledge is achieved by incorporating a secondary source of information into the agents’ decision-making process. Here, accurate information provided by an observer is used to update empirical expectations.
The model shows that the same variation of the descriptive norm mechanism could lead to varying aggregate fraud levels across different fraud categories. Two empirically measured norm sensitivity distributions associated with different fraud categories can be selected into the model to see the different aggregate outcomes.

Peer reviewed Reduced Mobility Transition Model (R-MoTMo)
Gesine A. Steudle Steffen Fürst Sarah Wolf | Published Tuesday, December 06, 2022The Mobility Transition Model (MoTMo) is a large scale agent-based model to simulate the private mobility demand in Germany until 2035. Here, we publish a very much reduced version of this model (R-MoTMo) which is designed to demonstrate the basic modelling ideas; the aim is by abstracting from the (empirical, technological, geographical, etc.) details to examine the feed-backs of individual decisions on the socio-technical system.

Peer reviewed The Viability of the Social-Ecological Agroecosystem (ViSA) Spatial Agent-based Model
Mostafa Shaaban | Published Monday, March 25, 2024ViSA 2.0.0 is an updated version of ViSA 1.0.0 aiming at integrating empirical data of a new use case that is much smaller than in the first version to include field scale analysis. Further, the code of the model is simplified to make the model easier and faster. Some features from the previous version have been removed.
It simulates decision behaviors of different stakeholders showing demands for ecosystem services (ESS) in agricultural landscape. It investigates conditions and scenarios that can increase the supply of ecosystem services while keeping the viability of the social system by suggesting different mixes of initial unit utilities and decision rules.
Peer reviewed Correlated Random Walk (NetLogo)
Viktoriia Radchuk Thibault Fronville Uta Berger | Published Tuesday, May 09, 2023 | Last modified Monday, December 18, 2023This is NetLogo code that presents two alternative implementations of Correlated Random Walk (CRW):
- 1. drawing the turning angles from the uniform distribution, i.e. drawing the angle with the same probability from a certain given range;
- 2. drawing the turning angles from von Mises distribution.
The move lengths are drawn from the lognormal distribution with the specified parameters.
Correlated Random Walk is used to represent the movement of animal individuals in two-dimensional space. When modeled as CRW, the direction of movement at any time step is correlated with the direction of movement at the previous time step. Although originally used to describe the movement of insects, CRW was later shown to sufficiently well describe the empirical movement data of other animals, such as wild boars, caribous, sea stars.
…

Peer reviewed Share: bottom-up disaster information management
Vittorio Nespeca Tina Comes Frances Brazier | Published Monday, December 05, 2022This model is intended to study the way information is collectively managed (i.e. shared, collected, processed, and stored) in a system and how it performs during a crisis or disaster. Performance is assessed in terms of the system’s ability to provide the information needed to the actors who need it when they need it. There are two main types of actors in the simulation, namely communities and professional responders. Their ability to exchange information is crucial to improve the system’s performance as each of them has direct access to only part of the information they need.
In a nutshell, the following occurs during a simulation. Due to a disaster, a series of randomly occurring disruptive events takes place. The actors in the simulation need to keep track of such events. Specifically, each event generates information needs for the different actors, which increases the information gaps (i.e. the “piles” of unaddressed information needs). In order to reduce the information gaps, the actors need to “discover” the pieces of information they need. The desired behavior or performance of the system is to keep the information gaps as low as possible, which is to address as many information needs as possible as they occur.
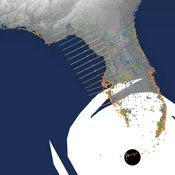
Peer reviewed CHIME ABM of Hurricane Evacuation
Sean Bergin C Michael Barton Joshua Watts Joshua Alland Rebecca Morss | Published Monday, October 18, 2021 | Last modified Tuesday, January 04, 2022The Communicating Hazard Information in the Modern Environment (CHIME) agent-based model (ABM) is a Netlogo program that facilitates the analysis of information flow and protective decisions across space and time during hazardous weather events. CHIME ABM provides a platform for testing hypotheses about collective human responses to weather forecasts and information flow, using empirical data from historical hurricanes. The model uses real world geographical and hurricane data to set the boundaries of the simulation, and it uses historical hurricane forecast information from the National Hurricane Center to initiate forecast information flow to citizen agents in the model.
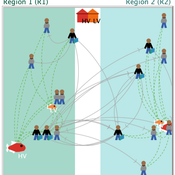
Peer reviewed Small-Trade Model
Emilie Lindkvist Blanca Gonzalez-Mon Örjan Bodin Maja Schlüter | Published Wednesday, July 28, 2021The purpose of this model is to understand the role of trade networks and their interaction with different fish resources, for fish provision. The model is developed based on a multi-methods approach, combining agent-based modeling, network analysis and qualitative data based on a small-scale fisheries study case. The model can be used to investigate both how trade network structures are embedded in a social-ecological context and the trade processes that occur within them, to analyze how they lead to emergent outcomes related to the resilience of fish provision. The model processes are informed by qualitative data analysis, and the social network analysis of an empirical fish trade network. The network analysis can be used to investigate diverse network structures to perform model experiments, and their influence on model outcomes.
The main outcomes we study are 1) the overexploitation of fish resources and 2) the availability and variability of fish provision to satisfy different market demands, and 3) individual traders’ fish supply at the micro-level. The model has two types of trader agents, seller and dealer. The model reveals that the characteristics of the trade networks, linked to different trader types (that have different roles in those networks), can affect the resilience of fish provision.

Peer reviewed Neighbor Influenced Energy Retrofit (NIER) agent-based model
Eric Boria | Published Friday, April 03, 2020The NIER model is intended to add qualitative variables of building owner types and peer group scales to existing energy efficiency retrofit adoption models. The model was developed through a combined methodology with qualitative research, which included interviews with key stakeholders in Cleveland, Ohio and Detroit and Grand Rapids, Michigan. The concepts that the NIER model adds to traditional economic feasibility studies of energy retrofit decision-making are differences in building owner types (reflecting strategies for managing buildings) and peer group scale (neighborhoods of various sizes and large-scale Districts). Insights from the NIER model include: large peer group comparisons can quickly raise the average energy efficiency values of Leader and Conformist building owner types, but leave Stigma-avoider owner types as unmotivated to retrofit; policy interventions such as upgrading buildings to energy-related codes at the point of sale can motivate retrofits among the lowest efficient buildings, which are predominantly represented by the Stigma-avoider type of owner; small neighborhood peer groups can successfully amplify normal retrofit incentives.
Peer reviewed From Individual Fuzzy Cognitive Maps to Agent Based Models: Modeling Multi-Factorial and Multi-stakeholder Decision-Making for Water Scarcity
Sara Mehryar | Published Monday, March 04, 2019 | Last modified Wednesday, August 28, 2019This model simulates different farmers’ decisions and actions to adapt to the water scarce situation. This simulation helps to investigate how farmers’ strategies may impact macro-behavior of the social-ecological system i.e. overall groundwater use change and emigration of farmers. The environmental variables’ behavior and behavioral rules of stakeholders are captured with Fuzzy Cognitive Map (FCM) that is developed with both qualitative and quantitative data, i.e. stakeholders’ knowledge and empirical data from studies. This model have been used to compare the impact of different water scarcity policies on overall groundwater use in a farming community facing water scarcity.
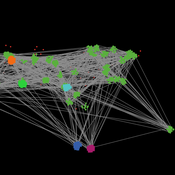
Peer reviewed Hohokam Trade Networks Model
Joshua Watts | Published Sunday, October 26, 2014The Hohokam Trade Networks Model focuses on key features of the Hohokam economy to explore how differences in trade network topologies may show up in the archaeological record. The model is set in the Phoenix Basin of central Arizona, AD 200-1450.
Displaying 10 of 92 results empirical clear search