About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 167 results for "Nuno Pinto" clear search

Peer reviewed NoD-Neg: A Non-Deterministic model of affordable housing Negotiations
Aya Badawy Richard Kingston Nuno Pinto | Published Sunday, September 08, 2024The Non-Deterministic model of affordable housing Negotiations (NoD-Neg) is designed for generating hypotheses about the possible outcomes of negotiating affordable housing obligations in new developments in England. By outcomes we mean, the probabilities of failing the negotiation and/or the different possibilities of agreement.
The model focuses on two negotiations which are key in the provision of affordable housing. The first is between a developer (DEV) who is submitting a planning application for approval and the relevant Local Planning Authority (LPA) who is responsible for reviewing the application and enforcing the affordable housing obligations. The second negotiation is between the developer and a Registered Social Landlord (RSL) who buys the affordable units from the developer and rents them out. They can negotiate the price of selling the affordable units to the RSL.
The model runs the two negotiations on the same development project several times to enable agents representing stakeholders to apply different negotiation tactics (different agendas and concession-making tactics), hence, explore the different possibilities of outcomes.
The model produces three types of outputs: (i) histograms showing the distribution of the negotiation outcomes in all the simulation runs and the probability of each outcome; (ii) a data file with the exact values shown in the histograms; and (iii) a conversation log detailing the exchange of messages between agents in each simulation run.
Evolution of shedding games
Marco Janssen | Published Sunday, May 16, 2010 | Last modified Saturday, April 27, 2013This simulates the evolution of rules of shedding games based on cultural group selection. A number of groups play shedding games and evaluate the consequences on the average length and the difficulty
Drafting agent-based modeling into basketball analytics
Matthew Oldham | Published Tuesday, February 19, 2019An agent-based simulation of a game of basketball. The model implements most components of a standard game of basketball. Additionally, the model allows the user to test for the effect of two separate cognitive biases – the hot-hand effect and a belief in the team’s franchise player.
Peer reviewed Agent-Based Insight into Eco-Choices: Simulating the Fast Fashion Shift
Daria Soboleva Angel Sánchez | Published Wednesday, August 07, 2024The present model was created and used for the study titled ``Agent-Based Insight into Eco-Choices: Simulating the Fast Fashion Shift.” The model is implemented in the multi-agent programmable environment NetLogo 6.3.0. The model is designed to simulate the behavior and decision-making processes of individuals (agents) in a social network. It focuses on how agents interact with their peers, social media, and government campaigns, specifically regarding their likelihood to purchase fast fashion.
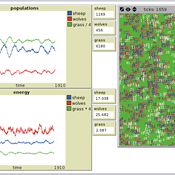
Peer reviewed PPHPC - Predator-Prey for High-Performance Computing
Nuno Fachada | Published Saturday, August 08, 2015 | Last modified Wednesday, November 25, 2015PPHPC is a conceptual model for studying and evaluating implementation strategies for spatial agent-based models (SABMs). It is a realization of a predator-prey dynamic system, and captures important SABMs characteristics.
A multithreaded PPHPC replication in Java
Nuno Fachada | Published Saturday, October 31, 2015 | Last modified Tuesday, January 19, 2016A multithreaded replication of the PPHPC model in Java for testing different ABM parallelization strategies.
Integrate land use policies into the agent-based model to simulate land use change
Jing Gao | Published Sunday, June 09, 2024Detailed information will be presented after the journal paper is published.

MCR Model
Davide Secchi Nuno R Barros De Oliveira | Published Friday, July 22, 2016 | Last modified Saturday, January 23, 2021The aim of the model is to define when researcher’s assumptions of dependence or independence of cases in multiple case study research affect the results — hence, the understanding of these cases.

BehaviorSpace tutorial model
Colin Wren | Published Wednesday, March 23, 2016This is based off my previous Profiler tutorial model, but with an added tutorial on converting it into a model usable with BehaviorSpace, and creating a BehaviorSpace experiment.
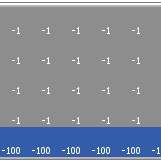
Cliff Walking with Q-Learning NetLogo Extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
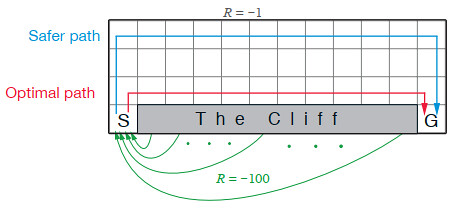
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension
Displaying 10 of 167 results for "Nuno Pinto" clear search