About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 156 results for "Andrea Rapisarda" clear search
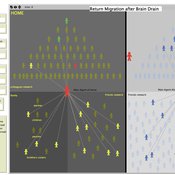
RETURN MIGRATION AFTER BRAIN DRAIN: A SIMULATION APPROACH
Alessio Emanuele Biondo Alessandro Pluchino Andrea Rapisarda | Published Friday, June 21, 2013This model, realized on the NetLogo platform, compares utility levels at home and abroad to simulate agents’ migration and their eventual return. Our model is based on two fundamental individual features, i.e. risk aversion and initial expectation, which characterize the dynamics of different agents according to the evolution of their social contacts.
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
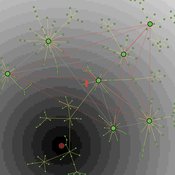
A Consumer in the Jungle of Product Differentiation
Alessio Emanuele Biondo Alfio Giarlotta Alessandro Pluchino Andrea Rapisarda | Published Tuesday, December 22, 2015Building upon the distance-based Hotelling’s differentiation idea, we describe the behavioral experience of several prototypes of consumers, who walk a hypothetical cognitive path in an attempt to maximize their satisfaction.
Peer reviewed Modelling the Social Complexity of Reputation and Status Dynamics
André Grow Andreas Flache | Published Wednesday, February 01, 2017 | Last modified Wednesday, January 23, 2019The purpose of this model is to illustrate the use of agent-based computational modelling in the study of the emergence of reputation and status beliefs in a population.
Vaccine adoption with outgroup aversion using Cleveland area data
bruce1809 | Published Monday, July 31, 2023 | Last modified Sunday, August 06, 2023This model takes concepts from a JASSS paper this is accepted for the October, 2023 edition and applies the concepts to empirical data from counties surrounding and including Cleveland Ohio. The agent-based model has a proportional number of agents in each of the counties to represent the correct proportions of adults in these counties. The adoption decision probability uses the equations from Bass (1969) as adapted by Rand & Rust (2011). It also includes the Outgroup aversion factor from Smaldino, who initially had used a different imitation model on line grid. This model uses preferential attachment network as a metaphor for social networks influencing adoption. The preferential network can be adjusted in the model to be created based on both nodes preferred due to higher rank as well as a mild preference for nodes of a like group.
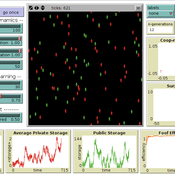
“Food for all” (FFD)
José Santos José Manuel Galán Andreas Angourakis Andrea L Balbo | Published Friday, April 25, 2014 | Last modified Monday, April 08, 2019“Food for all” (FFD) is an agent-based model designed to study the evolution of cooperation for food storage. Households face the social dilemma of whether to store food in a corporate stock or to keep it in a private stock.

Peer reviewed An Agent-Based Model of Status Construction in Task Focused Groups
André Grow Andreas Flache Rafael Wittek | Published Sunday, May 18, 2014 | Last modified Tuesday, June 16, 2015The model simulates interactions in small, task focused groups that might lead to the emergence of status beliefs among group members.
Peer reviewed A Model of Global Diversity and Local Consensus in Status Beliefs
André Grow Andreas Flache Rafael Wittek | Published Wednesday, March 01, 2017 | Last modified Wednesday, October 25, 2017This model makes it possible to explore how network clustering and resistance to changing existing status beliefs might affect the spontaneous emergence and diffusion of such beliefs as described by status construction theory.
Simulating the Ridesharing Economy: The Individual Agent Metro-Washington Area Ridesharing Model (IAMWARM)
Joseph A. E. Shaheen | Published Thursday, January 27, 2022This is a ridesharing model (Uber/Lyft) of the larger Washington DC metro area. The model can be modified (Netlogo 6.x) relatively easily and be adapted to any metro area. Please cite generously (this was a lot of work) and please cite the paper, not the comses model.
Link to the paper published in “Complex Adaptive Systems” here: https://link.springer.com/chapter/10.1007/978-3-030-20309-2_7
Citation: Shaheen J.A.E. (2019) Simulating the Ridesharing Economy: The Individual Agent Metro-Washington Area Ridesharing Model (IAMWARM). In: Carmichael T., Collins A., Hadžikadić M. (eds) Complex Adaptive Systems. Understanding Complex Systems. Springer, Cham. https://doi.org/10.1007/978-3-030-20309-2_7
Schelling Model of the City of Salzburg
Andreas Schlagbauer | Published Monday, December 05, 2022The purpose of the model is to better understand, how different factors for human residential choices affect the city’s segregation pattern. Therefore, a Schelling (1971) model was extended to include ethnicity, income, and affordability and applied to the city of Salzburg. So far, only a few studies have tried to explore the effect of multiple factors on the residential pattern (Sahasranaman & Jensen, 2016, 2018; Yin, 2009). Thereby, models using multiple factors can produce more realistic results (Benenson et al., 2002). This model and the corresponding thesis aim to fill that gap.
Displaying 10 of 156 results for "Andrea Rapisarda" clear search