About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 632 results agent-based clear search

Peer reviewed Historical Letters
Malte Vogl Bernardo Buarque Jascha Merijn Schmitz Aleksandra Kaye | Published Thursday, May 16, 2024 | Last modified Friday, May 24, 2024A letter sending model with historically informed initial positions to reconstruct communication and archiving processes in the Republic of Letters, the 15th to 17th century form of scholarship.
The model is aimed at historians, willing to formalize historical assumptions about the letter sending process itself and allows in principle to set heterogeneous social roles, e.g. to evaluate the role of gender or social status in the formation of letter exchange networks. The model furthermore includes a pruning process to simulate the loss of letters to critically asses the role of biases e.g. in relation to gender, geographical regions, or power structures, in the creation of empirical letter archives.
Each agent has an initial random topic vector, expressed as a RGB value. The initial positions of the agents are based on a weighted random draw based on data from [2]. In each step, agents generate two neighbourhoods for sending letters and potential targets to move towards. The probability to send letters is a self-reinforcing process. After each sending the internal topic of the receiver is updated as a movement in abstract space by a random amount towards the letters topic.
…

Peer reviewed The Megafauna Hunting Pressure Model
Isaac Ullah Miriam C. Kopels | Published Friday, February 16, 2024 | Last modified Friday, October 11, 2024The Megafaunal Hunting Pressure Model (MHPM) is an interactive, agent-based model designed to conduct experiments to test megaherbivore extinction hypotheses. The MHPM is a model of large-bodied ungulate population dynamics with human predation in a simplified, but dynamic grassland environment. The overall purpose of the model is to understand how environmental dynamics and human predation preferences interact with ungulate life history characteristics to affect ungulate population dynamics over time. The model considers patterns in environmental change, human hunting behavior, prey profitability, herd demography, herd movement, and animal life history as relevant to this main purpose. The model is constructed in the NetLogo modeling platform (Version 6.3.0; Wilensky, 1999).
Peer reviewed A financial market with zero intelligence agents
edgarkp | Published Wednesday, March 27, 2024The model’s aim is to represent the price dynamics under very simple market conditions, given the values adopted by the user for the model parameters. We suppose the market of a financial asset contains agents on the hypothesis they have zero-intelligence. In each period, a certain amount of agents are randomly selected to participate to the market. Each of these agents decides, in a equiprobable way, between proposing to make a transaction (talk = 1) or not (talk = 0). Again in an equiprobable way, each participating agent decides to speak on the supply (ask) or the demand side (bid) of the market, and proposes a volume of assets, where this number is drawn randomly from a uniform distribution. The granularity depends on various factors, including market conventions, the type of assets or goods being traded, and regulatory requirements. In some markets, high granularity is essential to capture small price movements accurately, while in others, coarser granularity is sufficient due to the nature of the assets or goods being traded
Peer reviewed An extended replication of Abelson's and Bernstein's community referendum simulation
Klaus G. Troitzsch | Published Friday, October 25, 2019 | Last modified Friday, August 25, 2023This is an extended replication of Abelson’s and Bernstein’s early computer simulation model of community referendum controversies which was originally published in 1963 and often cited, but seldom analysed in detail. This replication is in NetLogo 6.3.0, accompanied with an ODD+D protocol and class and sequence diagrams.
This replication replaces the original scales for attitude position and interest in the referendum issue which were distributed between 0 and 1 with values that are initialised according to a normal distribution with mean 0 and variance 1 to make simulation results easier compatible with scales derived from empirical data collected in surveys such as the European Value Study which often are derived via factor analysis or principal component analysis from the answers to sets of questions.
Another difference is that this model is not only run for Abelson’s and Bernstein’s ten week referendum campaign but for an arbitrary time in order that one can find out whether the distributions of attitude position and interest in the (still one-dimensional) issue stabilise in the long run.
Peer reviewed Street Dog Sim - An agent based model for investigating strategies of free roaming dog control.
Andrew Calinger-yoak | Published Wednesday, July 19, 2023This is an agent-based model constructed in Netlogo v6.2.2 which seeks to provide a simple but flexible tool for researchers and dog-population managers to help inform management decisions.
It replicates the basic demographic processes including:
* reproduction
* natural death
* dispersal
…

Peer reviewed A Computational Simulation for Task Allocation Influencing Performance in the Team System
Shaoni Wang | Published Friday, November 11, 2022 | Last modified Thursday, April 06, 2023This model system aims to simulate the whole process of task allocation, task execution and evaluation in the team system through a feasible method. On the basis of Complex Adaptive Systems (CAS) theory and Agent-based Modelling (ABM) technologies and tools, this simulation system attempts to abstract real-world teams into MAS models. The author designs various task allocation strategies according to different perspectives, and the interaction among members is concerned during the task-performing process. Additionally, knowledge can be acquired by such an interaction process if members encounter tasks they cannot handle directly. An artificial computational team is constructed through ABM in this simulation system, to replace real teams and carry out computational experiments. In all, this model system has great potential for studying team dynamics, and model explorers are encouraged to expand on this to develop richer models for research.
Peer reviewed SIM-VOLATILE: Adoption of emerging circular technologies in the waste-treatment sector
Siavash Farahbakhsh | Published Wednesday, December 14, 2022The SIM-VOLATILE model is a technology adoption model at the population level. The technology, in this model, is called Volatile Fatty Acid Platform (VFAP) and it is in the frame of the circular economy. The technology is considered an emerging technology and it is in the optimization phase. Through the adoption of VFAP, waste-treatment plants will be able to convert organic waste into high-end products rather than focusing on the production of biogas. Moreover, there are three adoption/investment scenarios as the technology enables the production of polyhydroxyalkanoates (PHA), single-cell oils (SCO), and polyunsaturated fatty acids (PUFA). However, due to differences in the processing related to the products, waste-treatment plants need to choose one adoption scenario.
In this simulation, there are several parameters and variables. Agents are heterogeneous waste-treatment plants that face the problem of circular economy technology adoption. Since the technology is emerging, the adoption decision is associated with high risks. In this regard, first, agents evaluate the economic feasibility of the emerging technology for each product (investment scenarios). Second, they will check on the trend of adoption in their social environment (i.e. local pressure for each scenario). Third, they combine these two economic and social assessments with an environmental assessment which is their environmental decision-value (i.e. their status on green technology). This combination gives the agent an overall adaptability fitness value (detailed for each scenario). If this value is above a certain threshold, agents may decide to adopt the emerging technology, which is ultimately depending on their predominant adoption probabilities and market gaps.
Peer reviewed PolicySpace2: modeling markets and endogenous public policies
Bernardo Furtado | Published Thursday, February 25, 2021 | Last modified Friday, January 14, 2022Policymakers decide on alternative policies facing restricted budgets and uncertain future. Designing public policies is further difficult due to the need to decide on priorities and handle effects across policies. Housing policies, specifically, involve heterogeneous characteristics of properties themselves and the intricacy of housing markets and the spatial context of cities. We propose PolicySpace2 (PS2) as an adapted and extended version of the open source PolicySpace agent-based model. PS2 is a computer simulation that relies on empirically detailed spatial data to model real estate, along with labor, credit, and goods and services markets. Interaction among workers, firms, a bank, households and municipalities follow the literature benchmarks to integrate economic, spatial and transport scholarship. PS2 is applied to a comparison among three competing public policies aimed at reducing inequality and alleviating poverty: (a) house acquisition by the government and distribution to lower income households, (b) rental vouchers, and (c) monetary aid. Within the model context, the monetary aid, that is, smaller amounts of help for a larger number of households, makes the economy perform better in terms of production, consumption, reduction of inequality, and maintenance of financial duties. PS2 as such is also a framework that may be further adapted to a number of related research questions.
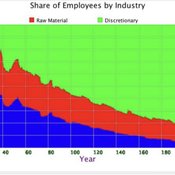
Peer reviewed A Macroeconomic Model of a Closed Economy
Ian Stuart | Published Saturday, May 08, 2021 | Last modified Wednesday, June 23, 2021This model/program presents a “three industry model” that may be particularly useful for macroeconomic simulations. The main purpose of this program is to demonstrate a mechanism in which the relative share of labor shifts between industries.
Care has been taken so that it is written in a self-documenting way so that it may be useful to anyone that might build from it or use it as an example.
This model is not intended to match a specific economy (and is not calibrated to do so) but its particular minimalist implementation may be useful for future research/development.
…
Peer reviewed Routes & Rumours 0.1.1
Martin Hinsch Jakub Bijak Oliver Reinhardt | Published Tuesday, July 12, 2022Routes & Rumours is an agent-based model of (forced) human migration. We model the formation of migration routes under the assumption that migrants have limited geographical knowledge concerning the transit area and rely to a large degree on information obtained from other migrants.
Displaying 10 of 632 results agent-based clear search