About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 148 results for "Jos%C3%A9 I Santos" clear search

Walk Away in groups
Athena Aktipis | Published Thursday, March 17, 2016This NetLogo model implements the Walk Away strategy in a spatial public goods game, where individuals have the ability to leave groups with insufficient levels of cooperation.

Peer reviewed NoD-Neg: A Non-Deterministic model of affordable housing Negotiations
Aya Badawy Richard Kingston Nuno Pinto | Published Sunday, September 08, 2024The Non-Deterministic model of affordable housing Negotiations (NoD-Neg) is designed for generating hypotheses about the possible outcomes of negotiating affordable housing obligations in new developments in England. By outcomes we mean, the probabilities of failing the negotiation and/or the different possibilities of agreement.
The model focuses on two negotiations which are key in the provision of affordable housing. The first is between a developer (DEV) who is submitting a planning application for approval and the relevant Local Planning Authority (LPA) who is responsible for reviewing the application and enforcing the affordable housing obligations. The second negotiation is between the developer and a Registered Social Landlord (RSL) who buys the affordable units from the developer and rents them out. They can negotiate the price of selling the affordable units to the RSL.
The model runs the two negotiations on the same development project several times to enable agents representing stakeholders to apply different negotiation tactics (different agendas and concession-making tactics), hence, explore the different possibilities of outcomes.
The model produces three types of outputs: (i) histograms showing the distribution of the negotiation outcomes in all the simulation runs and the probability of each outcome; (ii) a data file with the exact values shown in the histograms; and (iii) a conversation log detailing the exchange of messages between agents in each simulation run.

Maze with Q-Learning NetLogo extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This is a re-implementation of a the NetLogo model Maze (ROOP, 2006).
This re-implementation makes use of the Q-Learning NetLogo Extension to implement the Q-Learning, which is done only with NetLogo native code in the original implementation.
Cliff Walking with Q-Learning NetLogo Extension
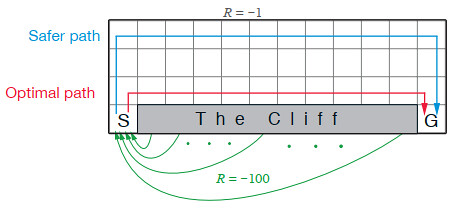
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension
MarPEM: An Agent Based Model to Explore the Effects of Policy Instruments on the Transition of the Maritime Fuel System
G Bas K De Boo Am Vaes - Van De Hulsbeek I Nikolic | Published Thursday, June 15, 2017MarPEM is an agent-based model that can be used to study the effects of policy instruments on the transition away from HFO.
Large-scale land acqusitions and smallholder food security
Tim Williams | Published Thursday, September 16, 2021Large-scale land acquisitions (LSLAs) threaten smallholder livelihoods globally. Despite more than a decade of research on the LSLA phenomenon, it remains a challenge to identify governance conditions that may foster beneficial outcomes for both smallholders and investors. One potentially promising strategy toward this end is contract farming (CF), which more directly involves smallholder households in commodity production than conditions of acquisition and displacement.
To improve understanding of how CF may mediate the outcomes of LSLAs, we developed an agent-based model of smallholder livelihoods, which we used as a virtual laboratory to experiment on a range of hypothetical LSLA and CF implementation scenarios.
The model represents a community of smallholder households in a mixed crop-livestock system. Each agent farms their own land and manages a herd of livestock. Agents can also engage in off-farm employment, for which they earn a fixed wage and compete for a limited number of jobs. The principal model outputs include measures of household food security (representing access to a single, staple food crop) and agricultural production (of a single, staple food crop).
…
Replicating the Macy & Sato Model: Trust, Cooperation and Market Formation in the U.S. and Japan
Oliver Will | Published Saturday, August 29, 2009 | Last modified Saturday, April 27, 2013A replication of the model “Trust, Cooperation and Market Formation in the U.S. and Japan” by Michael W. Macy and Yoshimichi Sato.
Shellmound Trade
Henrique de Sena Kozlowski | Published Saturday, June 15, 2024This model simulates different trade dynamics in shellmound (sambaqui) builder communities in coastal Southern Brazil. It features two simulation scenarios, one in which every site is the same and another one testing different rates of cooperation. The purpose of the model is to analyze the networks created by the trade dynamics and explore the different ways in which sambaqui communities were articulated in the past.
How it Works?
There are a few rules operating in this model. In either mode of simulation, each tick the agents will produce an amount of resources based on the suitability of the patches inside their occupation-radius, after that the procedures depend on the trade dynamic selected. For BRN? the agents will then repay their owed resources, update their reputation value and then trade again if they need to. For GRN? the agents will just trade with a connected agent if they need to. After that the agents will then consume a random amount of resources that they own and based on that they will grow (split) into a new site or be removed from the simulation. The simulation runs for 1000 ticks. Each patch correspond to a 300x300m square of land in the southern coast of Santa Catarina State in Brazil. Each agent represents a shellmound (sambaqui) builder community. The data for the world were made from a SRTM raster image (1 arc-second) in ArcMap. The sites can be exported into a shapefile (.shp) vector to display in ArcMap. It uses a UTM Sirgas 2000 22S projection system.
Expectation-Based Bayesian Belief Revision
C Merdes Ulrike Hahn Momme Von Sydow | Published Monday, June 19, 2017 | Last modified Monday, August 06, 2018This model implements a Bayesian belief revision model that contrasts an ideal agent in possesion of true likelihoods, an agent using a fixed estimate of trusting its source of information, and an agent updating its trust estimate.
Correlated random walk (Javascript)
Thibault Fronville Viktoriia Radchuk Uta Berger | Published Tuesday, May 09, 2023The first simple movement models used unbiased and uncorrelated random walks (RW). In such models of movement, the direction of the movement is totally independent of the previous movement direction. In other words, at each time step the direction, in which an individual is moving is completely random. This process is referred to as a Brownian motion.
On the other hand, in correlated random walks (CRW) the choice of the movement directions depends on the direction of the previous movement. At each time step, the movement direction has a tendency to point in the same direction as the previous one. This movement model fits well observational movement data for many animal species.
The presented agent based model simulated the movement of the agents as a correlated random walk (CRW). The turning angle at each time step follows the Von Mises distribution with a ϰ of 10. The closer ϰ gets to zero, the closer the Von Mises distribution becomes uniform. The larger ϰ gets, the more the Von Mises distribution approaches a normal distribution concentrated around the mean (0°).
In this script the turning angles (following the Von Mises distribution) are generated based on the the instructions from N. I. Fisher 2011.
This model is implemented in Javascript and can be used as a building block for more complex agent based models that would rely on describing the movement of individuals with CRW.
Displaying 10 of 148 results for "Jos%C3%A9 I Santos" clear search