About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 93 results for "Andrew Yoak" clear search
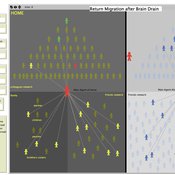
RETURN MIGRATION AFTER BRAIN DRAIN: A SIMULATION APPROACH
Alessio Emanuele Biondo Alessandro Pluchino Andrea Rapisarda | Published Friday, June 21, 2013This model, realized on the NetLogo platform, compares utility levels at home and abroad to simulate agents’ migration and their eventual return. Our model is based on two fundamental individual features, i.e. risk aversion and initial expectation, which characterize the dynamics of different agents according to the evolution of their social contacts.
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
This paper presents an agent-based model to study the dynamics of city-state systems in a constrained environment with limited space and resources. The model comprises three types of agents: city-states, villages, and battalions, where city-states, the primary decision-makers, can build villages for food production and recruit battalions for defense and aggression. In this setting, simulation results, generated through a multi-parameter grid sampling, suggest that risk-seeking strategies are more effective in high-cost scenarios, provided that the production rate is sufficiently high. Also, the model highlights the role of output productivity in defining which strategic preferences are successful in a long-term scenario, with higher outputs supporting more aggressive expansion and military actions, while resource limitations compel more conservative strategies focused on survival and resource conservation. Finally, the results suggest the existence of a non-linear effect of diminishing returns in strategic investments on successful strategies, emphasizing the need for careful resource allocation in a competitive environment.
A Consumer in the Jungle of Product Differentiation
Alessio Emanuele Biondo Alfio Giarlotta Alessandro Pluchino Andrea Rapisarda | Published Tuesday, December 22, 2015Building upon the distance-based Hotelling’s differentiation idea, we describe the behavioral experience of several prototypes of consumers, who walk a hypothetical cognitive path in an attempt to maximize their satisfaction.
Modeling the decline of labor-sharing in highly variable environments
Andres Baeza-Castro Marco Janssen | Published Tuesday, April 02, 2019The rapid environmental changes currently underway in many dry regions of the world, and the deep uncertainty about their consequences, underscore a critical challenge for sustainability: how to maintain cooperation that ensures the provision of natural resources when the benefits of cooperating are variable, sometimes uncertain, and often limited. We present an agent-based model that simulates the economic decisions of households to engage, or not, in labor-sharing agreements under different scenarios of water supply, water variability, and socio-environmental risk. We formulate the model to investigate the consequences of environmental variability on the fate of labor-sharing agreements between farmers. The economic decisions were implemented in the framework of prospect theory.
Change and Senescence
André Martins | Published Tuesday, November 10, 2020Agers and non-agers agent compete over a spatial landscape. When two agents occupy the same grid, who will survive is decided by a random draw where chances of survival are proportional to fitness. Agents have offspring each time step who are born at a distance b from the parent agent and the offpring inherits their genetic fitness plus a random term. Genetic fitness decreases with time, representing environmental change but effective non-inheritable fitness can increase as animals learn and get bigger.
Modeling information Asymmetries in Tourism
Rodolfo Baggio Jacopo Baggio | Published Monday, January 09, 2012 | Last modified Saturday, April 27, 2013A very simple model elaborated to explore what may happens when buyers (travelers) have more information than sellers (tourist destinations)
Value Chain Marketing (VCM)
Stephanie Hintze | Published Monday, April 14, 2014 | Last modified Thursday, October 16, 2014Inspired by the SKIN model, the basic concept here is to model the acceptance and implementation of supplier innovations. This model includes three types of agents comprising suppliers, manufacturers and applicators.
Homophily as a process generating social networks: insights from Social Distance Attachment model
Szymon Talaga Andrzej Nowak | Published Tuesday, September 17, 2019This is code repository for the paper “Homophily as a process generating social networks: insights from Social Distance Attachment model”.
It provides all information, code and data necessary to replicate all the simulations and analyses presented in the paper.
This document contains the overall instruction as well as description of the content of the repository.
Details regarding particular stages are documented within source files as comments.

Introducing two extensions of Schelling's segregation model
Andreas Flache Carlos A. de Matos Fernandes | Published Monday, January 25, 2021Schelling famously proposed an extremely simple but highly illustrative social mechanism to understand how strong ethnic segregation could arise in a world where individuals do not necessarily want it. Schelling’s simple computational model is the starting point for our extensions in which we build upon Wilensky’s original NetLogo implementation of this model. Our two NetLogo models can be best studied while reading our chapter “Agent-based Computational Models” (Flache and de Matos Fernandes, 2021). In the chapter, we propose 10 best practices to elucidate how agent-based models are a unique method for providing and analyzing formally precise, and empirically plausible mechanistic explanations of puzzling social phenomena, such as segregation, in the social world. Our chapter addresses in particular analytical sociologists who are new to ABMs.
In the first model (SegregationExtended), we build on Wilensky’s implementation of Schelling’s model which is available in NetLogo library (Wilensky, 1997). We considerably extend this model, allowing in particular to include larger neighborhoods and a population with four groups roughly resembling the ethnic composition of a contemporary large U.S. city. Further features added concern the possibility to include random noise, and the addition of a number of new outcome measures tuned to highlight macro-level implications of the segregation dynamics for different groups in the agent society.
In SegregationDiscreteChoice, we further modify the model incorporating in particular three new features: 1) heterogeneous preferences roughly based on empirical research categorizing agents into low, medium, and highly tolerant within each of the ethnic subgroups of the population, 2) we drop global thresholds (%-similar-wanted) and introduce instead a continuous individual-level single-peaked preference function for agents’ ideal neighborhood composition, and 3) we use a discrete choice model according to which agents probabilistically decide whether to move to a vacant spot or stay in the current spot by comparing the attractiveness of both locations based on the individual preference functions.
…
Displaying 10 of 93 results for "Andrew Yoak" clear search