About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 110 results social simulation clear search
Open Peer Review Model
Federico Bianchi | Published Monday, May 24, 2021This is an agent-based model of a population of scientists alternatively authoring or reviewing manuscripts submitted to a scholarly journal for peer review. Peer-review evaluation can be either ‘confidential’, i.e. the identity of authors and reviewers is not disclosed, or ‘open’, i.e. authors’ identity is disclosed to reviewers. The quality of the submitted manuscripts vary according to their authors’ resources, which vary according to the number of publications. Reviewers can assess the assigned manuscript’s quality either reliably of unreliably according to varying behavioural assumptions, i.e. direct/indirect reciprocation of past outcome as authors, or deference towards higher-status authors.
Simulation model replicating the five different games that were run during a workshop of the TISSS Lab
tissslab | Published Friday, April 30, 2021The three-day participatory workshop organized by the TISSS Lab had 20 participants who were academics in different career stages ranging from university student to professor. For each of the five games, the participants had to move between tables according to some pre-specified rules. After the workshop both the participant’s perception of the games’ complexities and the participants’ satisfaction with the games were recorded.
In order to obtain additional objective measures for the games’ complexities, these games were also simulated using this simulation model here. Therefore, the simulation model is an as-accurate-as-possible reproduction of the workshop games: it has 20 participants moving between 5 different tables. The rules that specify who moves when vary from game to game. Just to get an idea, Game 3 has the rule: “move if you’re sitting next to someone who is waring white or no socks”.
An exact description of the workshop games and the associated simulation models can be found in the paper “The relation between perceived complexity and happiness with decision situations: searching for objective measures in social simulation games”.
AIforGoodSimulator - Modeling Covid-19 Spread and Potential Interventions in Refugee Camps
Shyaam Ramkumar Woi Sok Oh | Published Thursday, March 18, 2021The Netlogo model is a conceptualization of the Moria refugee camp, capturing the household demographics of refugees in the camp, a theoretical friendship network based on values, and an abstraction of their daily activities. The model then simulates how Covid-19 could spread through the camp if one refugee is exposed to the virus, utilizing transmission probabilities and the stages of disease progression of Covid-19 from susceptible to exposed to asymptomatic / symptomatic to mild / severe to recovered from literature. The model also incorporates various interventions - PPE, lockdown, isolation of symptomatic refugees - to analyze how they could mitigate the spread of the virus through the camp.
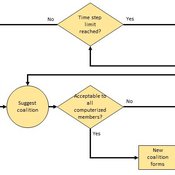
Heuristic Algorithm for Generating Strategic Coalition Structures
Andrew Collins Daniele Vernon-Bido | Published Monday, October 12, 2020The purpose of the model is to generate coalition structures of different glove games, using a specially designed algorithm. The coalition structures can be are later analyzed by comparing them to core partitions of the game used. Core partitions are coalition structures where no subset of players has an incentive to form a new coalition.
The algorithm used in this model is an advancement of the algorithm found in Collins & Frydenlund (2018). It was used used to generate the results in Vernon-Bido & Collins (2021).
A spatial model of resource-consumer dynamics
Guus Ten Broeke George Ak Van Voorn Arend Ligtenberg Jaap Molenaar | Published Wednesday, January 11, 2017 | Last modified Thursday, September 17, 2020The model simulates agents in a spatial environment competing for a common resource that grows on patches. The resource is converted to energy, which is needed for performing actions and for surviving.
RecovUS: An Agent-Based Model of Post-Disaster Household Recovery
Saeed Moradi | Published Thursday, July 30, 2020The purpose of this model is to explain the post-disaster recovery of households residing in their own single-family homes and to predict households’ recovery decisions from drivers of recovery. Herein, a household’s recovery decision is repair/reconstruction of its damaged house to the pre-disaster condition, waiting without repair/reconstruction, or selling the house (and relocating). Recovery drivers include financial conditions and functionality of the community that is most important to a household. Financial conditions are evaluated by two categories of variables: costs and resources. Costs include repair/reconstruction costs and rent of another property when the primary house is uninhabitable. Resources comprise the money required to cover the costs of repair/reconstruction and to pay the rent (if required). The repair/reconstruction resources include settlement from the National Flood Insurance (NFI), Housing Assistance provided by the Federal Emergency Management Agency (FEMA-HA), disaster loan offered by the Small Business Administration (SBA loan), a share of household liquid assets, and Community Development Block Grant Disaster Recovery (CDBG-DR) fund provided by the Department of Housing and Urban Development (HUD). Further, household income determines the amount of rent that it can afford. Community conditions are assessed for each household based on the restoration of specific anchors. ASNA indexes (Nejat, Moradi, & Ghosh 2019) are used to identify the category of community anchors that is important to a recovery decision of each household. Accordingly, households are indexed into three classes for each of which recovery of infrastructure, neighbors, or community assets matters most. Further, among similar anchors, those anchors are important to a household that are located in its perceived neighborhood area (Moradi, Nejat, Hu, & Ghosh 2020).
PaCE Austria Pilot Model
Ruth Meyer | Published Tuesday, June 30, 2020The objective of building a social simulation in the Populism and Civic Engagement (PaCE) project is to study the phenomenon of populism by mapping individual level political behaviour and explain the influence of agents on, and their interdependence with the respective political parties. Voters, political parties and – to some extent – the media can be viewed as forming a complex adaptive system, in which parties compete for citizens’ votes, voters decide on which party to vote for based on their respective positions with regard to particular issues, and the media may influence the salience of issues in the public debate.
This is the first version of a model exploring voting behaviour in Austria. It focusses on modelling the interaction of voters and parties in a political landscape; the effects of the media are not yet represented. Austria was chosen as a case study because it has an established populist party (the “Freedom Party” FPO), which has even been part of the government over the years.
Agent Based Integrated Assessment Model
Marcin Czupryna | Published Saturday, June 27, 2020Agent based approach to the class of the Integrated Assessment Models. An agent-based model (ABM) that focuses on the energy sector and climate relevant facts in a detailed way while being complemented with consumer goods, labour and capital markets to a minimal necessary extent.
Behavioural parallel trading systems
Marcin Czupryna | Published Friday, June 26, 2020This model simulates the behaviour of the agents in 3 wine markets parallel trading systems: Liv-ex, Auctions and additionally OTC market (finally not used). Behavioural aspects (impatience) is additionally modeled. This is an extention of parallel trading systems model with technical trading (momentum and contrarian) and noise trading.
Parallel trading systems
Marcin Czupryna | Published Friday, June 26, 2020The model simulates agents behaviour in wine market parallel trading systems: auctions, OTC and Liv-ex. Models are written in JAVA and use MASON framework. To run a simulation download source files with additional src folder with sobol.csv file. In WineSimulation.java set RESULTS_FOLDER parameter. Uses following external libraries mason19..jar, opencsv.jar, commons-lang3-3.5.jar and commons-math3-3.6.1.jar.
Displaying 10 of 110 results social simulation clear search