About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 92 results resources clear search
Importing a Roman transport network
Tom Brughmans | Published Sunday, September 30, 2018A draft model teaching how a Roman transport model can be imported into Netlogo, and the issues confronted when importing and reusing open access Roman datasets. This model is used for the tutorial:
Brughmans, T. (2018). Importing a Roman Transport network with Netlogo, Tutorial, https://archaeologicalnetworks.wordpress.com/resources/#transport .
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
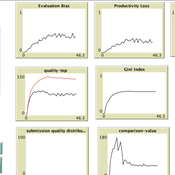
Peer Review Game
Federico Bianchi Francisco Grimaldo Giangiacomo Bravo Flaminio Squazzoni | Published Monday, April 30, 2018NetLogo software for the Peer Review Game model. It represents a population of scientists endowed with a proportion of a fixed pool of resources. At each step scientists decide how to allocate their resources between submitting manuscripts and reviewing others’ submissions. Quality of submissions and reviews depend on the amount of allocated resources and biased perception of submissions’ quality. Scientists can behave according to different allocation strategies by simply reacting to the outcome of their previous submission process or comparing their outcome with published papers’ quality. Overall bias of selected submissions and quality of published papers are computed at each step.
Cooperation Under Resources Pressure (CURP)
María Pereda José Manuel Galán Ordax José Santos | Published Monday, November 21, 2016 | Last modified Wednesday, April 25, 2018This is an agent-based model designed to explore the evolution of cooperation under changes in resources availability for a given population
05 CmLab V1.17 – Conservation of Money Laboratory
Garvin Boyle | Published Saturday, April 15, 2017In CmLab we explore the implications of the phenomenon of Conservation of Money in a modern economy. This is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, CmLab.
Formation of Lithic Assemblages v. 1
C Michael Barton Julien Riel-Salvatore | Published Thursday, September 04, 2014This model represents technological and ecological behaviors of mobile hunter-gatherers, in a variable environment, as they produce, use, and discard chipped stone artifacts. The results can be analyzed and compared with archaeological sites.
Feedback Loop Example: Forest Resource Transport
James Millington | Published Friday, December 21, 2012 | Last modified Saturday, April 27, 2013This model illustrates a positive ‘transport’ feedback loop in which lines with different resistance to flows of material result in variation in rates of change in linked entities.
Digital divide and opinion formation
Dongwon Lim | Published Friday, November 02, 2012 | Last modified Monday, May 20, 2013This model extends the bounded confidence model of Deffuant and Weisbuch. It introduces online contexts in which a person can deliver his or her opinion to several other persons. There are 2 additional parameters accessibility and connectivity.
Interactions between organizations and social networks in common-pool resource governance
Phesi Project | Published Monday, October 29, 2012 | Last modified Saturday, April 27, 2013Explores how social networks affect implementation of institutional rules in a common pool resource.
Hegmon's Model of Sharing
Sean Bergin | Published Thursday, May 02, 2013The purpose of Hegmon’s Sharing model is to develop an understanding of the effect sharing strategies have on household survival.
Displaying 10 of 92 results resources clear search