About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 138 results for "Andreas Ihrig" clear search
PSMED - Patagonia Simple Model of Ethnic Differentiation
Joan A Barceló J A Cuesta Florencia Del Castillo Ricardo Del Olmo José M Galán Laura Mameli Francisco J Miguel David Poza José I Santos Xavier Vilà | Published Tuesday, December 10, 2013Patagonia PSMED is an agent-based model designed to study a simple case of Evolution of Ethnic Differentiation. It replicates how can hunter-gatherer societies evolve and built cultural identities as a consequence of the way they interacted.
An agent-based model to simulate meat consumption behaviour of consumers in Britain
Andrea Scalco | Published Friday, October 18, 2019The current rate of production and consumption of meat poses a problem both to peoples’ health and to the environment. This work aims to develop a simulation of peoples’ meat consumption behaviour in Britain using agent-based modelling. The agents represent individual consumers. The key variables that characterise agents include sex, age, monthly income, perception of the living cost, and concerns about the impact of meat on the environment, health, and animal welfare. A process of peer influence is modelled with respect to the agents’ concerns. Influence spreads across two eating networks (i.e. co-workers and household members) depending on the time of day, day of the week, and agents’ employment status. Data from a representative sample of British consumers is used to empirically ground the model. Different experiments are run simulating interventions of application of social marketing campaigns and a rise in price of meat. The main outcome is the average weekly consumption of meat per consumer. A secondary outcome is the likelihood of eating meat.

Introducing two extensions of Schelling's segregation model
Andreas Flache Carlos A. de Matos Fernandes | Published Monday, January 25, 2021Schelling famously proposed an extremely simple but highly illustrative social mechanism to understand how strong ethnic segregation could arise in a world where individuals do not necessarily want it. Schelling’s simple computational model is the starting point for our extensions in which we build upon Wilensky’s original NetLogo implementation of this model. Our two NetLogo models can be best studied while reading our chapter “Agent-based Computational Models” (Flache and de Matos Fernandes, 2021). In the chapter, we propose 10 best practices to elucidate how agent-based models are a unique method for providing and analyzing formally precise, and empirically plausible mechanistic explanations of puzzling social phenomena, such as segregation, in the social world. Our chapter addresses in particular analytical sociologists who are new to ABMs.
In the first model (SegregationExtended), we build on Wilensky’s implementation of Schelling’s model which is available in NetLogo library (Wilensky, 1997). We considerably extend this model, allowing in particular to include larger neighborhoods and a population with four groups roughly resembling the ethnic composition of a contemporary large U.S. city. Further features added concern the possibility to include random noise, and the addition of a number of new outcome measures tuned to highlight macro-level implications of the segregation dynamics for different groups in the agent society.
In SegregationDiscreteChoice, we further modify the model incorporating in particular three new features: 1) heterogeneous preferences roughly based on empirical research categorizing agents into low, medium, and highly tolerant within each of the ethnic subgroups of the population, 2) we drop global thresholds (%-similar-wanted) and introduce instead a continuous individual-level single-peaked preference function for agents’ ideal neighborhood composition, and 3) we use a discrete choice model according to which agents probabilistically decide whether to move to a vacant spot or stay in the current spot by comparing the attractiveness of both locations based on the individual preference functions.
…
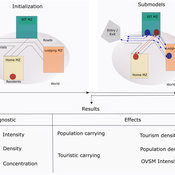
Peer reviewed ABM Overtourism Santa Marta
Janwar Moreno | Published Monday, October 23, 2023This model presents the simulation model of a city in the context of overtourism. The study area is the city of Santa Marta in Colombia. The purpose is to illustrate the spatial and temporal distribution of population and tourists in the city. The simulation analyzes emerging patterns that result from the interaction between critical components in the touristic urban system: residents, urban space, touristic sites, and tourists. The model is an Agent-Based Model (ABM) with the GAMA software. Also, it used public input data from statistical centers, geographical information systems, tourist websites, reports, and academic articles. The ABM includes assessing some measures used to address overtourism. This is a field of research with a low level of analysis for destinations with overtourism, but the ABM model allows it. The results indicate that the city has a high risk of overtourism, with spatial and temporal differences in the population distribution, and it illustrates the effects of two management measures of the phenomenon on different scales. Another interesting result is the proposed tourism intensity indicator (OVsm), taking into account that the tourism intensity indicators used by the literature on overtourism have an overestimation of tourism pressures.
Evaluating Government's Policies on Promoting Smart Metering Diffusion in Retail Electricity Markets
Tao Zhang | Published Monday, December 07, 2009 | Last modified Saturday, April 27, 2013This model is a market game for evaluating the effectiveness of the UK government’s 2008-2010 policy on promoting smart metering in the UK retail electricity market. We break down the policy into four
Feedback Loop Example: Wildland Fire Spread
James Millington | Published Friday, December 21, 2012 | Last modified Saturday, April 27, 2013This model is a replication of that described by Peterson (2002) and illustrates the ‘spread’ feedback loop type described in Millington (2013).
Recycling behavior of Chinese households
B Dijkhuizen M Van Den Hoven M Minderhoud N Wäckerlin Igor Nikolic | Published Monday, June 19, 2017 | Last modified Thursday, March 29, 2018The model represents empirically observed recycling behaviour of Chinese citizens, based on the theory of reasoned action (TRA), the theory of planned behaviour (TPB) and the theory of planned behaviour extended with situational factors (TPB+).

Segregation and Opinion Polarization
Thomas Feliciani Andreas Flache Jochem Tolsma | Published Wednesday, April 13, 2016This is a tool to explore the effects of groups´ spatial segregation on the emergence of opinion polarization. It embeds two opinion formation models: a model of negative (and positive) social influence and a model of persuasive argument exchange.
Can ethnic tolerance curb self-reinforcing school segregation? A theoretical Agent Based Model
Lucas Sage Andreas Flache | Published Monday, August 10, 2020Schelling and Sakoda prominently proposed computational models suggesting that strong ethnic residential segregation can be the unintended outcome of a self-reinforcing dynamic driven by choices of individuals with rather tolerant ethnic preferences. There are only few attempts to apply this view to school choice, another important arena in which ethnic segregation occurs. In the current paper, we explore with an agent-based theoretical model similar to those proposed for residential segregation, how ethnic tolerance among parents can affect the level of school segregation. More specifically, we ask whether and under which conditions school segregation could be reduced if more parents hold tolerant ethnic preferences. We move beyond earlier models of school segregation in three ways. First, we model individual school choices using a random utility discrete choice approach. Second, we vary the pattern of ethnic segregation in the residential context of school choices systematically, comparing residential maps in which segregation is unrelated to parents’ level of tolerance to residential maps reflecting their ethnic preferences. Third, we introduce heterogeneity in tolerance levels among parents belonging to the same group. Our simulation experiments suggest that ethnic school segregation can be a very robust phenomenon, occurring even when about half of the population prefers mixed to segregated schools. However, we also identify a “sweet spot” in the parameter space in which a larger proportion of tolerant parents makes the biggest difference. This is the case when parents have moderate preferences for nearby schools and there is only little residential segregation. Further experiments are presented that unravel the underlying mechanisms.

Peer reviewed Share: bottom-up disaster information management
Vittorio Nespeca Tina Comes Frances Brazier | Published Monday, December 05, 2022This model is intended to study the way information is collectively managed (i.e. shared, collected, processed, and stored) in a system and how it performs during a crisis or disaster. Performance is assessed in terms of the system’s ability to provide the information needed to the actors who need it when they need it. There are two main types of actors in the simulation, namely communities and professional responders. Their ability to exchange information is crucial to improve the system’s performance as each of them has direct access to only part of the information they need.
In a nutshell, the following occurs during a simulation. Due to a disaster, a series of randomly occurring disruptive events takes place. The actors in the simulation need to keep track of such events. Specifically, each event generates information needs for the different actors, which increases the information gaps (i.e. the “piles” of unaddressed information needs). In order to reduce the information gaps, the actors need to “discover” the pieces of information they need. The desired behavior or performance of the system is to keep the information gaps as low as possible, which is to address as many information needs as possible as they occur.
Displaying 10 of 138 results for "Andreas Ihrig" clear search