About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 774 results for "Blanca Gonzalez-Mon" clear search
Hollywood Underrepresentation Simulated Causes
Carmen Iasiello | Published Sunday, November 26, 2023Presented here is a socioeconomic agent-based model (ABM) to examine the Hollywood labor system as a network within a simulated movie labor market based on preferential attachment and compare the findings with 50 co-production ego networks during the 2015 movie year. Using the ABM, I test the role slight individual preference for racial and ethnic similarity within one’s own network at the microlevel and find that it is insufficient to explain the phenomena of racial and ethnic underrepresentation at the macrolevel. The ABM also includes the ability to test alternative explanations, such as overt opportunity loss as a possible explanation.
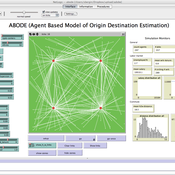
ABODE - Agent Based Model of Origin Destination Estimation
D Levinson | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013The agent based model matches origins and destinations using employment search methods at the individual level.

WealthDistribRes
Romulus-Catalin Damaceanu | Published Friday, May 04, 2012 | Last modified Saturday, April 27, 2013This model WealthDistribRes can be used to study the distribution of wealth in function of using a combination of resources classified in two renewable and nonrenewable.
SimDrink: An agent-based NetLogo model of young, heavy drinkers for conducting alcohol policy experiments
Nick Scott Michael Livingston Aaron Hart James Wilson David Moore Paul Dietze | Published Friday, September 25, 2015 | Last modified Thursday, October 15, 2015A proof-of-concept agent-based model ‘SimDrink’, which simulates a population of 18-25 year old heavy alcohol drinkers on a night out in Melbourne to provide a means for conducting policy experiments to inform policy decisions.
The Groundwater Commons Game
Juan Castilla-Rho Rodrigo Rojas | Published Thursday, May 11, 2017 | Last modified Saturday, September 16, 2017The Groundwater Commons Game synthesises and extends existing work on human cooperation and collective action, to elucidate possible determinants and pathways to regulatory compliance in groundwater systems globally.
Livestock drought insurance model
Felix John Birgit Müller Russell Toth Karin Frank Jürgen Groeneveld | Published Tuesday, December 19, 2017 | Last modified Saturday, April 14, 2018The model analyzes the economic and ecological effects of a provision of livestock drought insurance for dryland pastoralists. More precisely, it yields qualitative insights into how long-term herd and pasture dynamics change through insurance.
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
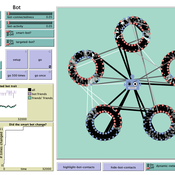
How do bots influence beliefs on social media? Why do beliefs propagated by social bots spread far and wide, yet does their direct influence appear to be limited?
This model extends Axelrod’s model for the dissemination of culture (1997), with a social bot agent–an agent who only sends information and cannot be influenced themselves. The basic network is a ring network with N agents connected to k nearest neighbors. The agents have a cultural profile with F features and Q traits per feature. When two agents interact, the sending agent sends the trait of a randomly chosen feature to the receiving agent, who adopts this trait with a probability equal to their similarity. To this network, we add a bot agents who is given a unique trait on the first feature and is connected to a proportion of the agents in the model equal to ‘bot-connectedness’. At each timestep, the bot is chosen to spread one of its traits to its neighbors with a probility equal to ‘bot-activity’.
The main finding in this model is that, generally, bot activity and bot connectedness are both negatively related to the success of the bot in spreading its unique message, in equilibrium. The mechanism is that very active and well connected bots quickly influence their direct contacts, who then grow too dissimilar from the bot’s indirect contacts to quickly, preventing indirect influence. A less active and less connected bot leaves more space for indirect influence to occur, and is therefore more successful in the long run.
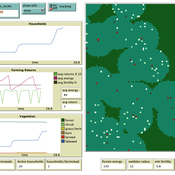
Swidden farming by individual households
C Michael Barton | Published Sunday, April 27, 2008 | Last modified Saturday, April 27, 2013Swidden Farming is designed to explore the dynamics of agricultural land management strategies.
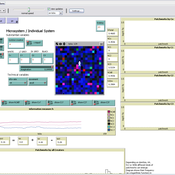
CRESY-I stands for CREativity from a SYstems perspetive, Model I. This is the base model in a series designed to describe a systems approach to creativity in terms of variation, selection and retention (VSR) subprocesses.
Displaying 10 of 774 results for "Blanca Gonzalez-Mon" clear search