About the CoMSES Model Library more info
Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 548 results for "Niklas Hase" clear search

Peer reviewed Agent-based model to simulate equilibria and regime shifts emerged in lake ecosystems
no contributors listed | Published Tuesday, January 25, 2022(An empty output folder named “NETLOGOexperiment” in the same location with the LAKEOBS_MIX.nlogo file is required before the model can be run properly)
The model is motivated by regime shifts (i.e. abrupt and persistent transition) revealed in the previous paleoecological study of Taibai Lake. The aim of this model is to improve a general understanding of the mechanism of emergent nonlinear shifts in complex systems. Prelimnary calibration and validation is done against survey data in MLYB lakes. Dynamic population changes of function groups can be simulated and observed on the Netlogo interface.
Main functional groups in lake ecosystems were modelled as super-individuals in a space where they interact with each other. They are phytoplankton, zooplankton, submerged macrophyte, planktivorous fish, herbivorous fish and piscivorous fish. The relationships between these functional groups include predation (e.g. zooplankton-phytoplankton), competition (phytoplankton-macrophyte) and protection (macrophyte-zooplankton). Each individual has properties in size, mass, energy, and age as physiological variables and reproduce or die according to predefined criteria. A system dynamic model was integrated to simulate external drivers.
Set biological and environmental parameters using the green sliders first. If the data of simulation are to be logged, set “Logdata” as true and input the name of the file you want the spreadsheet(.csv) to be called. You will need create an empty folder called “NETLOGOexperiment” in the same level and location with the LAKEOBS_MIX.nlogo file. Press “setup” to initialise the system and “go” to start life cycles.
Correlated random walk (Javascript)
Viktoriia Radchuk Uta Berger Thibault Fronville | Published Tuesday, May 09, 2023The first simple movement models used unbiased and uncorrelated random walks (RW). In such models of movement, the direction of the movement is totally independent of the previous movement direction. In other words, at each time step the direction, in which an individual is moving is completely random. This process is referred to as a Brownian motion.
On the other hand, in correlated random walks (CRW) the choice of the movement directions depends on the direction of the previous movement. At each time step, the movement direction has a tendency to point in the same direction as the previous one. This movement model fits well observational movement data for many animal species.
The presented agent based model simulated the movement of the agents as a correlated random walk (CRW). The turning angle at each time step follows the Von Mises distribution with a ϰ of 10. The closer ϰ gets to zero, the closer the Von Mises distribution becomes uniform. The larger ϰ gets, the more the Von Mises distribution approaches a normal distribution concentrated around the mean (0°).
In this script the turning angles (following the Von Mises distribution) are generated based on the the instructions from N. I. Fisher 2011.
This model is implemented in Javascript and can be used as a building block for more complex agent based models that would rely on describing the movement of individuals with CRW.
ForagerNet3_Demography_V3
Andrew White | Published Tuesday, November 29, 2016The ForagerNet3_Demography model is a non-spatial ABM designed to serve as a platform for exploring several aspects of hunter-gatherer demography.
Agent-based model for the socio-economic monitoring of visitor streams
Stefan Mohr | Published Saturday, January 20, 2018Due to the large extent of the Harz National Park, an accurate measurement of visitor numbers and their spatiotemporal distribution is not feasible. This model demonstrates the possibility to simulate the streams of visitors with ABM methodology.
Peer reviewed Casting: A Bio-Inspired Method for Restructuring Machine Learning Ensembles
Colin Lynch Bryan Daniels | Published Thursday, September 18, 2025The wisdom of the crowd refers to the phenomenon in which a group of individuals, each making independent decisions, can collectively arrive at highly accurate solutions—often more accurate than any individual within the group. This principle relies heavily on independence: if individual opinions are unbiased and uncorrelated, their errors tend to cancel out when averaged, reducing overall bias. However, in real-world social networks, individuals are often influenced by their neighbors, introducing correlations between decisions. Such social influence can amplify biases, disrupting the benefits of independent voting. This trade-off between independence and interdependence has striking parallels to ensemble learning methods in machine learning. Bagging (bootstrap aggregating) improves classification performance by combining independently trained weak learners, reducing bias. Boosting, on the other hand, explicitly introduces sequential dependence among learners, where each learner focuses on correcting the errors of its predecessors. This process can reinforce biases present in the data even if it reduces variance. Here, we introduce a new meta-algorithm, casting, which captures this biological and computational trade-off. Casting forms partially connected groups (“castes”) of weak learners that are internally linked through boosting, while the castes themselves remain independent and are aggregated using bagging. This creates a continuum between full independence (i.e., bagging) and full dependence (i.e., boosting). This method allows for the testing of model capabilities across values of the hyperparameter which controls connectedness. We specifically investigate classification tasks, but the method can be used for regression tasks as well. Ultimately, casting can provide insights for how real systems contend with classification problems.

Driving in the wrong direction? A co-evolutionary model of electric vehicle adoption and innovation
Daniel Torren-Peraire | Published Friday, July 11, 2025Car-centric societies face substantial challenges in moving towards sustainable
mobility systems, with internal combustion engine vehicles remaining a major
source of emissions. Electric vehicles play a critical role in addressing this challenge, yet their diffusion depends on the interaction of consumer behaviour, firm
innovation, and policy incentives. This paper develops an agent-based model to
examine these dynamics, calibrated on the data for the state of California over
2001-2023. In the model, heterogeneous car users influenced by their social peers
…
02 OamLab V1.10 - Open Atwood Machine Laboratory
Garvin Boyle | Published Saturday, January 31, 2015 | Last modified Thursday, April 13, 2017Using chains of replicas of Atwood’s Machine, this model explores implications of the Maximum Power Principle. It is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, EiLab.
03 MppLab V1.09 – Maximum Power Principle Laboratory
Garvin Boyle | Published Saturday, April 15, 2017Using webs of replicas of Atwood’s Machine, we explore implications of the Maximum Power Principle. This is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, CmLab.
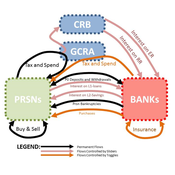
05 CmLab V1.17 – Conservation of Money Laboratory
Garvin Boyle | Published Saturday, April 15, 2017In CmLab we explore the implications of the phenomenon of Conservation of Money in a modern economy. This is one of a series of models exploring the dynamics of sustainable economics – PSoup, ModEco, EiLab, OamLab, MppLab, TpLab, CmLab.
Talent vs Luck: the role of randomness in success and failure
Alessandro Pluchino Alessio Emanuele Biondo Andrea Rapisarda | Published Monday, July 16, 2018The largely dominant meritocratic paradigm of highly competitive Western cultures is rooted on the belief that success is due mainly, if not exclusively, to personal qualities such as talent, intelligence, skills, smartness, efforts, willfulness, hard work or risk taking. Sometimes, we are willing to admit that a certain degree of luck could also play a role in achieving significant material success. But, as a matter of fact, it is rather common to underestimate the importance of external forces in individual successful stories. It is very well known that intelligence (or, more in general, talent and personal qualities) exhibits a Gaussian distribution among the population, whereas the distribution of wealth - often considered a proxy of success - follows typically a power law (Pareto law), with a large majority of poor people and a very small number of billionaires. Such a discrepancy between a Normal distribution of inputs, with a typical scale (the average talent or intelligence), and the scale invariant distribution of outputs, suggests that some hidden ingredient is at work behind the scenes. In a recent paper, with the help of this very simple agent-based model realized with NetLogo, we suggest that such an ingredient is just randomness. In particular, we show that, if it is true that some degree of talent is necessary to be successful in life, almost never the most talented people reach the highest peaks of success, being overtaken by mediocre but sensibly luckier individuals. As to our knowledge, this counterintuitive result - although implicitly suggested between the lines in a vast literature - is quantified here for the first time. It sheds new light on the effectiveness of assessing merit on the basis of the reached level of success and underlines the risks of distributing excessive honors or resources to people who, at the end of the day, could have been simply luckier than others. With the help of this model, several policy hypotheses are also addressed and compared to show the most efficient strategies for public funding of research in order to improve meritocracy, diversity and innovation.
Displaying 10 of 548 results for "Niklas Hase" clear search