About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 929 results for "M Van Den Hoven" clear search
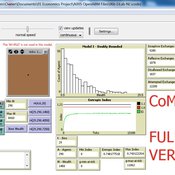
06b EiLab_Model_I_V5.00 NL
Garvin Boyle | Published Saturday, October 05, 2019EiLab - Model I - is a capital exchange model. That is a type of economic model used to study the dynamics of modern money which, strangely, is very similar to the dynamics of energetic systems. It is a variation on the BDY models first described in the paper by Dragulescu and Yakovenko, published in 2000, entitled “Statistical Mechanics of Money”. This model demonstrates the ability of capital exchange models to produce a distribution of wealth that does not have a preponderance of poor agents and a small number of exceedingly wealthy agents.
This is a re-implementation of a model first built in the C++ application called Entropic Index Laboratory, or EiLab. The first eight models in that application were labeled A through H, and are the BDY models. The BDY models all have a single constraint - a limit on how poor agents can be. That is to say that the wealth distribution is bounded on the left. This ninth model is a variation on the BDY models that has an added constraint that limits how wealthy an agent can be? It is bounded on both the left and right.
EiLab demonstrates the inevitable role of entropy in such capital exchange models, and can be used to examine the connections between changing entropy and changes in wealth distributions at a very minute level.
…

Peer reviewed MGA - Minimal Genetic Algorithm
Cosimo Leuci | Published Tuesday, September 03, 2019 | Last modified Thursday, January 30, 2020Genetic algorithms try to solve a computational problem following some principles of organic evolution. This model has educational purposes; it can give us an answer to the simple arithmetic problem on how to find the highest natural number composed by a given number of digits. We approach the task using a genetic algorithm, where the candidate solutions to the problem are represented by agents, that in logo programming environment are usually known as “turtles”.
Mobility, Resource Harvesting and Robustness of Social-Ecological Systems
Irene Perez Ibarra | Published Monday, September 24, 2012 | Last modified Saturday, April 27, 2013The model is a stylized representation of a social-ecological system of agents moving and harvesting a renewable resource. The purpose is to analyze how mobility affects sustainability. Experiments changing agents’ mobility, landscape and information governments have can be run.
On July 20th, James Holmes committed a mass shooting in a midnight showing of The Dark Knight Rises. The Aurora Colorado shooting was used as a test case to validate this framework for modeling mass shootings.
A data-informed bounded-confidence opinion dynamics model
Bruce Edmonds | Published Wednesday, March 10, 2021The simulation is a variant of the “ToRealSim OD variants - base v2.7” base model, which is based on the standard DW opinion dynamics model (but with the differences that rather than one agent per tick randomly influencing another, all agents randomly influence one other per tick - this seems to make no difference to the outcomes other than to scale simulation time). Influence can be made one-way by turning off the two-way? switch
Various additional variations and sources of noise are possible to test robustness of outcomes to these (compared to DW model).
In this version agent opinions change following the empirical data collected in some experiments (Takács et al 2016).
Such an algorithm leaves no role for the uncertainties in other OD models. [Indeed the data from (Takács et al 2016) indicates that there can be influence even when opinion differences are large - which violates a core assumption of these]. However to allow better comparison with other such models there is a with-un? switch which allows uncertainties to come into play. If this is on, then influence (according to above algorithm) is only calculated if the opinion difference is less than the uncertainty. If an agent is influenced uncertainties are modified in the same way as standard DW models.

Exploring social psychology theory for modelling farmer decision-making
James Millington | Published Tuesday, September 18, 2012 | Last modified Saturday, April 27, 2013To investigate the potential of using Social Psychology Theory in ABMs of natural resource use and show proof of concept, we present an exemplary agent-based modelling framework that explicitly represents multiple and hierarchical agent self-concepts
Hedonic and Eudaimonic Well-being Based Reward for Intrinsic Motivated Reinforcement Learning Agents
Yue Gao Shimon Edelman | Published Monday, March 21, 2016The code contains four experiments for well-being based IMRL reward features.
The spread of scientific methods within and between communities
Paul Smaldino Cailin O'Connor | Published Monday, August 29, 2022We consider scientific communities where each scientist employs one of two characteristic methods: an “adequate” method (A) and a “superior” method (S). The quality of methodology is relevant to the epistemic products of these scientists, and generate credit for their users. Higher-credit methods tend to be imitated, allowing to explore whether communities will adopt one method or the other. We use the model to examine the effects of (1) bias for existing methods, (2) competence to assess relative value of competing methods, and (3) two forms of interdisciplinarity: (a) the tendency for members of a scientific community to receive meaningful credit assignment from those outside their community, and (b) the tendency to consider new methods used outside their community. The model can be used to show how interdisciplinarity can overcome the effects of bias and incompetence for the spread of superior methods.
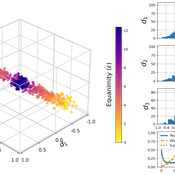
Weighted Balance Model of Issue Alignment and Polarization
David Garcia Simon Schweighofer | Published Sunday, October 08, 2023This model is pertinent to our JASSS publication “Raising the Spectrum of Polarization: Generating Issue Alignment with a Weighted Balance Opinion Dynamics Model”. It shows how, based on the mechanisms of our Weighted Balance Theory (a development of Fritz Heider’s Cognitive Balance Theory), agents can self-organize in a multi-dimensional opinion space and form an emergent ideological spectrum. The degree of issue alignment and polarization realized by the model depends mainly on the agent-specific ‘equanimity parameter’ epsilon.
EU language skills
Marco Civico | Published Sunday, July 07, 2024The objective of this agent-based model is to test different language education orientations and their consequences for the EU population in terms of linguistic disenfranchisement, that is, the inability of citizens to understand EU documents and parliamentary discussions should their native language(s) no longer be official. I will focus on the impact of linguistic distance and language learning. Ideally, this model would be a tool to help EU policy makers make informed decisions about language practices and education policies, taking into account their consequences in terms of diversity and linguistic disenfranchisement. The model can be used to force agents to make certain choices in terms of language skills acquisition. The user can then go on to compare different scenarios in which language skills are acquired according to different rationales. The idea is that, by forcing agents to adopt certain language learning strategies, the model user can simulate policies promoting the acquisition of language skills and get an idea of their impact. In this way the model allows not only to sketch various scenarios of the evolution of language skills among EU citizens, but also to estimate the level of disenfranchisement in each of these scenarios.
Displaying 10 of 929 results for "M Van Den Hoven" clear search