About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 871 results for "Wilfried van Sark" clear search
Introduction of a contact tracking app for outbreak control
Tim Verwaart | Published Tuesday, April 21, 2020The application of a smartphone application to register physical encounters between individuals is considered by public health authorities, as a means to reduce the number of infections in the 2020 COVID-19 pandemic. The general idea is that continuous registration of all other smartphones in the vicinity of an individual’s smartphone potentially enables early warning of the owners of the other smartphones, in case the individual is tested positive as infected. Those other individuals can then go into isolation and be considered for testing. The purpose of the present simulation is to explore the potential effects of this application on frequencies of infection, isolation, and positive and negative infection test results.
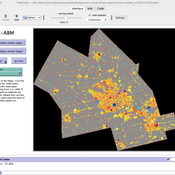
Retail Competition Agent-based Model
Jiaxin Zhang Derek Robinson | Published Sunday, January 03, 2021 | Last modified Wednesday, November 10, 2021The Retail Competition Agent-based Model (RC-ABM) is designed to simulate the retail competition system in the Region of Waterloo, Ontario, Canada, which which explicitly represents store competition behaviour. Through the RC-ABM, we aim to answer 4 research questions: 1) What is the level of correspondence between market share and revenue acquisition for an agent-based approach compared to a traditional location-allocation-based approach? 2) To what degree can the observed store spatial pattern be reproduced by competition? 3) To what degree are their path dependent patterns of retail success? 4) What is the relationship between retail survival and the endogenous geographic characteristics of stores and consumer expenditures?

Peer reviewed The Viability of the Social-Ecological Agroecosystem (ViSA) Spatial Agent-based Model
Mostafa Shaaban | Published Monday, March 25, 2024ViSA 2.0.0 is an updated version of ViSA 1.0.0 aiming at integrating empirical data of a new use case that is much smaller than in the first version to include field scale analysis. Further, the code of the model is simplified to make the model easier and faster. Some features from the previous version have been removed.
It simulates decision behaviors of different stakeholders showing demands for ecosystem services (ESS) in agricultural landscape. It investigates conditions and scenarios that can increase the supply of ecosystem services while keeping the viability of the social system by suggesting different mixes of initial unit utilities and decision rules.
Peer reviewed Correlated Random Walk (NetLogo)
Viktoriia Radchuk Thibault Fronville Uta Berger | Published Tuesday, May 09, 2023 | Last modified Monday, December 18, 2023This is NetLogo code that presents two alternative implementations of Correlated Random Walk (CRW):
- 1. drawing the turning angles from the uniform distribution, i.e. drawing the angle with the same probability from a certain given range;
- 2. drawing the turning angles from von Mises distribution.
The move lengths are drawn from the lognormal distribution with the specified parameters.
Correlated Random Walk is used to represent the movement of animal individuals in two-dimensional space. When modeled as CRW, the direction of movement at any time step is correlated with the direction of movement at the previous time step. Although originally used to describe the movement of insects, CRW was later shown to sufficiently well describe the empirical movement data of other animals, such as wild boars, caribous, sea stars.
…

Concession Forestry Modeling
Andrew Bell Rick L Riolo Jacqueline M Doremus Daniel G Brown Thomas P Lyon John Vandermeer Arun Agrawal | Published Thursday, January 23, 2014A logging agent builds roads based on the location of high-value hotspots, and cuts trees based on road access. A forest monitor sanctions the logger on observed infractions, reshaping the pattern of road development.

Peer reviewed DogFoxCDVspillover
Aniruddha Belsare Matthew Gompper | Published Thursday, March 16, 2017 | Last modified Tuesday, April 04, 2017The purpose of this model is to better understand the dynamics of a multihost pathogen in two host system comprising of high densities of domestic hosts and sympatric wildlife hosts susceptible to the pathogen.
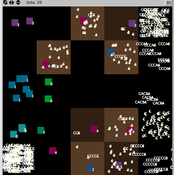
DiDIY Factory
Ruth Meyer | Published Tuesday, February 20, 2018The DiDIY-Factory model is a model of an abstract factory. Its purpose is to investigate the impact Digital Do-It-Yourself (DiDIY) could have on the domain of work and organisation.
DiDIY can be defined as the set of all manufacturing activities (and mindsets) that are made possible by digital technologies. The availability and ease of use of digital technologies together with easily accessible shared knowledge may allow anyone to carry out activities that were previously only performed by experts and professionals. In the context of work and organisations, the DiDIY effect shakes organisational roles by such disintermediation of experts. It allows workers to overcome the traditionally strict organisational hierarchies by having direct access to relevant information, e.g. the status of machines via real-time information systems implemented in the factory.
A simulation model of this general scenario needs to represent a more or less abstract manufacturing firm with supervisors, workers, machines and tasks to be performed. Experiments with such a model can then be run to investigate the organisational structure –- changing from a strict hierarchy to a self-organised, seemingly anarchic organisation.
U-TRANS Modelling Urban Transition with Coupled Housing and Labour Markets
B Furtado Jiaqi Ge | Published Monday, July 31, 2023We develop an agent-based model (U-TRANS) to simulate the transition of an abstract city under an industrial revolution. By coupling the labour and housing markets, we propose a holistic framework that incorporates the key interacting factors and micro processes during the transition. Using U-TRANS, we look at five urban transition scenarios: collapse, weak recovery, transition, enhanced training and global recruit, and find the model is able to generate patterns observed in the real world. For example, We find that poor neighbourhoods benefit the most from growth in the new industry, whereas the rich neighbourhoods do better than the rest when the growth is slow or the situation deteriorates. We also find a (subtle) trade-off between growth and equality. The strategy to recruit a large number of skilled workers globally will lead to higher growth in GDP, population and human capital, but it will also entail higher inequality and market volatility, and potentially create a divide between the local and international workers. The holistic framework developed in this paper will help us better understand urban transition and detect early signals in the process. It can also be used as a test-bed for policy and growth strategies to help a city during a major economic and technological revolution.
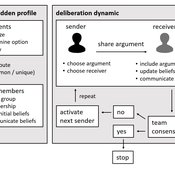
Agent-based model of team decision-making in hidden profile situations
Jonas Stein Andreas Flache Vincenz Frey | Published Thursday, April 20, 2023 | Last modified Friday, November 17, 2023The model presented here is extensively described in the paper ‘Talk less to strangers: How homophily can improve collective decision-making in diverse teams’ (forthcoming at JASSS). A full replication package reproducing all results presented in the paper is accessible at https://osf.io/76hfm/.
Narrative documentation includes a detailed description of the model, including a schematic figure and an extensive representation of the model in pseudocode.
The model develops a formal representation of a diverse work team facing a decision problem as implemented in the experimental setup of the hidden-profile paradigm. We implement a setup where a group seeks to identify the best out of a set of possible decision options. Individuals are equipped with different pieces of information that need to be combined to identify the best option. To this end, we assume a team of N agents. Each agent belongs to one of M groups where each group consists of agents who share a common identity.
The virtual teams in our model face a decision problem, in that the best option out of a set of J discrete options needs to be identified. Every team member forms her own belief about which decision option is best but is open to influence by other team members. Influence is implemented as a sequence of communication events. Agents choose an interaction partner according to homophily h and take turns in sharing an argument with an interaction partner. Every time an argument is emitted, the recipient updates her beliefs and tells her team what option she currently believes to be best. This influence process continues until all agents prefer the same option. This option is the team’s decision.
We propose here a computational model of school segregation that is aligned with a corresponding Schelling-type model of residential segregation. To adapt the model for application to school segregation, we move beyond previous work by combining two preference arguments in modeling parents’ school choice, preferences for the ethnic composition of a school and preferences for minimizing the travelling distance to the school.
Displaying 10 of 871 results for "Wilfried van Sark" clear search