About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 37 results Extension clear search
Wolf-sheep predation Netlogo model, extended, with foresight
andreapolicarpi Guido Fioretti | Published Wednesday, September 16, 2020 | Last modified Tuesday, April 13, 2021This model is an extension of the Netlogo Wolf-sheep predation model by U.Wilensky (1997). This extended model studies several different behavioural mechanisms that wolves and sheep could adopt in order to enhance their survivability, and their overall impact on global equilibrium of the system.
HomininSpace
Fulco Scherjon | Published Friday, November 25, 2016 | Last modified Tuesday, October 06, 2020A modelling system to simulate Neanderthal demography and distribution in a reconstructed Western Europe for the late Middle Paleolithic.
Peer review model with heterogeneous grade language
Thomas Feliciani Ramanathan Moorthy Pablo Lucas Kalpana Shankar | Published Thursday, May 07, 2020This ABM re-implements and extends the simulation model of peer review described in Squazzoni & Gandelli (Squazzoni & Gandelli, 2013 - doi:10.18564/jasss.2128) (hereafter: ‘SG’). The SG model was originally developed for NetLogo and is also available in CoMSES at this link.
The purpose of the original SG model was to explore how different author and reviewer strategies would impact the outcome of a journal peer review system on an array of dimensions including peer review efficacy, efficiency and equality. In SG, reviewer evaluation consists of a continuous variable in the range [0,1], and this evaluation scale is the same for all reviewers. Our present extension to the SG model allows to explore the consequences of two more realistic assumptions on reviewer evaluation: (1) that the evaluation scale is discrete (e.g. like in a Likert scale); (2) that there may be differences among their interpretation of the grades of the evaluation scale (i.e. that the grade language is heterogeneous).
Artificial Long House Valley-Black Mesa
Amy Warren Lisa Sattenspiel | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
PluchinoEtAl_ExtendedByAC
Andre Costopoulos | Published Tuesday, September 03, 2019 | Last modified Friday, January 31, 2020Extension of Pluchino et al.’s 2018 success vs talent model, to allow talented individuals to mitigate unlucky events.
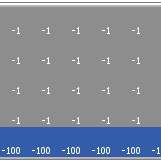
Cliff Walking with Q-Learning NetLogo Extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This model implements a classic scenario used in Reinforcement Learning problem, the “Cliff Walking Problem”. Consider the gridworld shown below (SUTTON; BARTO, 2018). This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked “The Cliff.” Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start (SUTTON; BARTO, 2018).
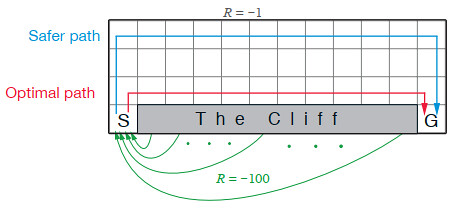
The problem is solved in this model using the Q-Learning algorithm. The algorithm is implemented with the support of the NetLogo Q-Learning Extension

Maze with Q-Learning NetLogo extension
Kevin Kons Fernando Santos | Published Tuesday, December 10, 2019This is a re-implementation of a the NetLogo model Maze (ROOP, 2006).
This re-implementation makes use of the Q-Learning NetLogo Extension to implement the Q-Learning, which is done only with NetLogo native code in the original implementation.
MERCURY extension: population
Tom Brughmans | Published Thursday, May 23, 2019This model is an extended version of the original MERCURY model (https://www.comses.net/codebases/4347/releases/1.1.0/ ) . It allows for experiments to be performed in which empirically informed population sizes of sites are included, that allow for the scaling of the number of tableware traders with the population of settlements, and for hypothesised production centres of four tablewares to be used in experiments.
Experiments performed with this population extension and substantive interpretations derived from them are published in:
Hanson, J.W. & T. Brughmans. In press. Settlement scale and economic networks in the Roman Empire, in T. Brughmans & A.I. Wilson (ed.) Simulating Roman Economies. Theories, Methods and Computational Models. Oxford: Oxford University Press.
…
Neolithic Spread Model Version 1.0
Sean Bergin Michael Barton Salvador Pardo Gordo Joan Bernabeu Auban | Published Thursday, December 11, 2014 | Last modified Monday, December 31, 2018This model simulates different spread hypotheses proposed for the introduction of agriculture on the Iberian peninsula. We include three dispersal types: neighborhood, leapfrog, and ideal despotic distribution (IDD).
Network structures tutorial
Tom Brughmans | Published Sunday, September 30, 2018 | Last modified Tuesday, October 02, 2018A draft model with some useful code for creating different network structures using the Netlogo NW extension. This model is used for the following tutorial:
Brughmans, T. (2018). Network structures and assembling code in Netlogo, Tutorial, https://archaeologicalnetworks.wordpress.com/resources/#structures .
Displaying 10 of 37 results Extension clear search