About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 116 results for "Roberto Cesar Betini" clear search
Feedback Loop Example: Wildland Fire Spread
James Millington | Published Friday, December 21, 2012 | Last modified Saturday, April 27, 2013This model is a replication of that described by Peterson (2002) and illustrates the ‘spread’ feedback loop type described in Millington (2013).
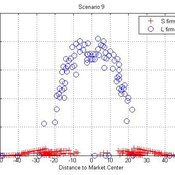
Micro-level Adaptation, Macro-level Selection, and the Dynamics of Market Partitioning
César García-Díaz | Published Monday, October 19, 2015 | Last modified Monday, October 19, 2015This model simulates the emergence of a dual market structure from firm-level interaction. Firms are profit-seeking, and demand is represented by a unimodal distribution of consumers along a set of taste positions.
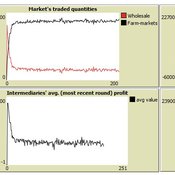
Market-level effects of firm-level adaptation and intermediation in networked markets of fresh foods: a case study in Colombia.
César García-Díaz | Published Sunday, April 12, 2020 | Last modified Sunday, April 12, 2020This a model developed as a part of the paper Mejía, G. & García-Díaz, C. (2018). Market-level effects of firm-level adaptation and intermediation in networked markets of fresh foods: a case study in Colombia. Agricultural Systems 160: 132-142.
It simulates the competition dynamics of the potato market in Bogotá, Colombia. The model explores the economic impact of intermediary actors on the potato supply chain.
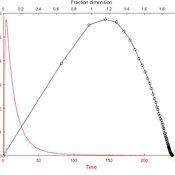
The Coevolution of the Firm and the Product Attribute Space
César García-Díaz | Published Friday, May 22, 2020This model inspects the performance of firms as the product attribute space changes, which evolves as a consequence of firms’ actions. Firms may create new product variants by dragging demand from other existing variants. Firms decide whether to open new product variants, to invade existing ones, or to keep their variant portfolio. At each variant there is a Cournot competition each round. Competition is nested since many firms compete at many variants simultaneously, affecting firm composition at each location (variant).
After the Cournot outcomes, at each round firms decide whether to (i) keep their existing product variant niche, (ii) invade an existing variant, (iii) create a new variant, or (iv) abandon a variant. Firms’ profits across their niche take into consideration the niche-width cost and the cost of opening a new variant.
The influence of cognitive diversity on networked search and coordination
César García-Díaz | Published Wednesday, April 03, 2024Agent-based models of organizational search have long investigated how exploitative and exploratory behaviors shape and affect performance on complex landscapes. To explore this further, we build a series of models where agents have different levels of expertise and cognitive capabilities, so they must rely on each other’s knowledge to navigate the landscape. Model A investigates performance results for efficient and inefficient networks. Building on Model B, it adds individual-level cognitive diversity and interaction based on knowledge similarity. Model C then explores the performance implications of coordination spaces. Results show that totally connected networks outperform both hierarchical and clustered network structures when there are clear signals to detect neighbor performance. However, this pattern is reversed when agents must rely on experiential search and follow a path-dependent exploration pattern.
A model of opinion dynamics based on formal argumentation: application to the diffusion of the vegetarian diet
Patrick Taillandier Nicolas Salliou Rallou Thomopoulos | Published Monday, March 15, 2021This generic agent-based model simulates the evolution of agent’s opinions through their exchange of arguments.
The idea behind this model is to explicitly represent the process of mental deliberation of agents from arguments to an opinion, through the use of Dung’s argumentation framework complemented by a structured description of arguments. An application of the model on the diffusion of vegetarian diets is proposed.
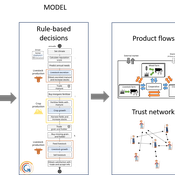
MIXTRUST - crop-livestock interactions at regional level
Myriam Grillot Aurélien Peter | Published Tuesday, February 25, 2025The basic idea behind developing MIXTRUST was to represent a network of agricultural stakeholders composed of farmers and a cooperative in a mixed landscape to test its performances in response to risks. A mixed landscape here is a landscape where crop and livestock systems interact by the intermediary of material flows of agricultural products. It can be within mixed farms, or between farms, often specialized, (e.g. straw-manure).
Between Pleasure and Contentment: Evolutionary Dynamics of Some Possible Parameters of Happiness
Yue Gao Shimon Edelman | Published Saturday, March 12, 2016 | Last modified Wednesday, March 16, 2016We build a computational model to investigate, in an evolutionary setting, a series of questions pertaining to happiness.
Agent Based Integrated Assessment Model
Marcin Czupryna | Published Saturday, June 27, 2020Agent based approach to the class of the Integrated Assessment Models. An agent-based model (ABM) that focuses on the energy sector and climate relevant facts in a detailed way while being complemented with consumer goods, labour and capital markets to a minimal necessary extent.
Agent-Based Model of Social Care with Kinship Networks
Eric Silverman Umberto Gostoli | Published Thursday, October 14, 2021The purpose of this model is the simulation of social care provision in the UK, in which individual agents can decide to provide informal care, or pay for private care, for their loved ones. Agents base these decisions on factors including their own health, employment status, financial resources, relationship to the individual in need and geographical location. The model simulates care provision as a negotiation process conducted between agents across their kinship networks, with agents with stronger familial relationships to the recipient being more likely to attempt to allocate time to care provision. The model also simulates demographic change, the impact of socioeconomic status, and allows agents to relocate and change jobs or reduce working hours in order to provide care.
Despite the relative lack of empirical data in this model, the model is able to reproduce plausible patterns of social care provision. The inclusion of detailed economic and behavioural mechanisms allows this model to serve as a useful policy development tool; complex behavioural interventions can be implemented in simulation and tested on a virtual population before applying them in real-world contexts.
Displaying 10 of 116 results for "Roberto Cesar Betini" clear search