About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 146 results for "Jeffrey C Schank" clear search
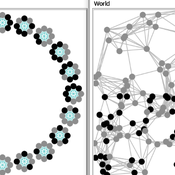
Two agent-based models of cooperation in dynamic groups and fixed social networks
Carlos A. de Matos Fernandes | Published Thursday, January 20, 2022Both models simulate n-person prisoner dilemma in groups (left figure) where agents decide to C/D – using a stochastic threshold algorithm with reinforcement learning components. We model fixed (single group ABM) and dynamic groups (bad-barrels ABM). The purpose of the bad-barrels model is to assess the impact of information during meritocratic matching. In the bad-barrels model, we incorporated a multidimensional structure in which agents are also embedded in a social network (2-person PD). We modeled a random and homophilous network via a random spatial graph algorithm (right figure).
Opinion dynamics and collective risk perception: An ABM model of institutional and media communication about disasters - Code and Datasets
danielevilone | Published Tuesday, October 06, 2020The O.R.E. (Opinions on Risky Events) model describes how a population of interacting individuals process information about a risk of natural catastrophe. The institutional information gives the official evaluation of the risk; the agents receive this communication, process it and also speak to each other processing further the information. The description of the algorithm (as it appears also in the paper) can be found in the attached file OREmodel_description.pdf.
The code (ORE_model.c), written in C, is commented. Also the datasets (inputFACEBOOK.txt and inputEMAILs.txt) of the real networks utilized with this model are available.
For any questions/requests, please write me at [email protected]

The PARSO_demo Model
Davide Secchi | Published Tuesday, November 05, 2019This model explores different aspects of the formation of urban neighbourhoods where residents believe in values distant from those dominant in society. Or, at least, this is what the Danish government beliefs when they discuss their politics about parallel societies. This simulation is set to understand (a) whether these alternative values areas form and what determines their formation, (b) if they are linked to low or no income residents, and (c) what happens if they disappear from the map. All these three points are part of the Danish government policy. This agent-based model is set to understand the boundaries and effects of this policy.
Eliminating hepatitis C virus as a public health threat among HIV-positive men who have sex with men
Nick Scott Mark Stoove David P Wilson Olivia Keiser Carol El-Hayek Joseph Doyle Margaret Hellard | Published Wednesday, October 12, 2016 | Last modified Sunday, December 16, 2018We compare three model estimates for the time and treatment requirements to eliminate HCV among HIV-positive MSM in Victoria, Australia: a compartmental model; an ABM parametrized by surveillance data; and an ABM with a more heterogeneous population.
Replication of an agent-based model using the Replication Standard
Jiaxin Zhang Derek Robinson | Published Sunday, January 20, 2019 | Last modified Saturday, July 18, 2020This model is a replication model which is constructed based on the existing model used by the following article:
Brown, D.G. and Robinson, D.T., 2006. Effects of heterogeneity in residential preferences on an agent-based model of urban sprawl. Ecology and society, 11(1).
The original model is called SLUCE’s Original Model for Experimentation (SOME). In Brown and Robinson (2006)’s article, the SOME model was used to explore the impacts of heterogeneity in residential location selections on the research of urban sprawl. The original model was constructed using Objective-C language based on SWARM platform. This replication model is built by NetLogo language on NetLogo platform. We successfully replicate that model and demonstrated the reliability and replicability of it.

The purpose of the study is to unpack and explore a potentially beneficial role of sharing metacognitive information within a group when making repeated decisions about common pool resource (CPR) use.
We explore the explanatory power of sharing metacognition by varying (a) the individual errors in judgement (myside-bias); (b) the ways of reaching a collective judgement (metacognition-dependent), (c) individual knowledge updating (metacognition- dependent) and d) the decision making context.
The model (AgentEx-Meta) represents an extension to an existing and validated model reflecting behavioural CPR laboratory experiments (Schill, Lindahl & Crépin, 2015; Lindahl, Crépin & Schill, 2016). AgentEx-Meta allows us to systematically vary the extent to which metacognitive information is available to agents, and to explore the boundary conditions of group benefits of metacognitive information.
An Agent-Based Model of an Insurance Market driven by Supply and Demand with Imperfectly Estimated Strategies in C#
Rei England | Published Sunday, September 24, 2023This is a simulation of an insurance market where the premium moves according to the balance between supply and demand. In this model, insurers set their supply with the aim of maximising their expected utility gain while operating under imperfect information about both customer demand and underlying risk distributions.
There are seven types of insurer strategies. One type follows a rational strategy within the bounds of imperfect information. The other six types also seek to maximise their utility gain, but base their market expectations on a chartist strategy. Under this strategy, market premium is extrapolated from trends based on past insurance prices. This is subdivided according to whether the insurer is trend following or a contrarian (counter-trend), and further depending on whether the trend is estimated from short-term, medium-term, or long-term data.
Customers are modelled as a whole and allocated between insurers according to available supply. Customer demand is calculated according to a logit choice model based on the expected utility gain of purchasing insurance for an average customer versus the expected utility gain of non-purchase.
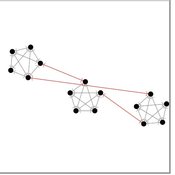
The influence of cognitive diversity on networked search and coordination
Cesar Garcia-Diaz | Published Wednesday, April 03, 2024Agent-based models of organizational search have long investigated how exploitative and exploratory behaviors shape and affect performance on complex landscapes. To explore this further, we build a series of models where agents have different levels of expertise and cognitive capabilities, so they must rely on each other’s knowledge to navigate the landscape. Model A investigates performance results for efficient and inefficient networks. Building on Model B, it adds individual-level cognitive diversity and interaction based on knowledge similarity. Model C then explores the performance implications of coordination spaces. Results show that totally connected networks outperform both hierarchical and clustered network structures when there are clear signals to detect neighbor performance. However, this pattern is reversed when agents must rely on experiential search and follow a path-dependent exploration pattern.
A minimal assumption based agent based simulation model of the emergence of technological innovation
Yuan Zhao Roland Ortt Bernhard Katzy | Published Sunday, October 19, 2014This simulation model is to simulate the emergence of technological innovation processes from the hypercycles perspective.
An Agent-Based Model of an Insurer's Estimated Capital Requirement in a Simple Insurance Market with Imperfect Information in C#
Rei England | Published Sunday, September 24, 2023This is an agent-based model of a simple insurance market with two types of agents: customers and insurers. Insurers set premium quotes for each customer according to an estimation of their underlying risk based on past claims data. Customers either renew existing contracts or else select the cheapest quote from a subset of insurers. Insurers then estimate their resulting capital requirement based on a 99.5% VaR of their aggregate loss distributions. These estimates demonstrate an under-estimation bias due to the winner’s curse effect.
Displaying 10 of 146 results for "Jeffrey C Schank" clear search