About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 216 results for "Daniel C Peart" clear search
A replication and extension of the Taylor's Simulation Model of Insurance Market Dynamics in C#
Rei England | Published Sunday, September 24, 2023A simple model is constructed using C# in order to to capture key features of market dynamics, while also producing reasonable results for the individual insurers. A replication of Taylor’s model is also constructed in order to compare results with the new premium setting mechanism. To enable the comparison of the two premium mechanisms, the rest of the model set-up is maintained as in the Taylor model. As in the Taylor example, homogeneous customers represented as a total market exposure which is allocated amongst the insurers.
In each time period, the model undergoes the following steps:
1. Insurers set competitive premiums per exposure unit
2. Losses are generated based on each insurer’s share of the market exposure
3. Accounting results are calculated for each insurer
…
Human Resource Management Parameter Experimentation Tool
Carmen Iasiello | Published Thursday, May 07, 2020 | Last modified Thursday, February 25, 2021The agent based model presented here is an explicit instantiation of the Two-Factor Theory (Herzberg et al., 1959) of worker satisfaction and dissatisfaction. By utilizing agent-based modeling, it allows users to test the empirically found variations on the Two-Factor Theory to test its application to specific industries or organizations.
Iasiello, C., Crooks, A.T. and Wittman, S. (2020), The Human Resource Management Parameter Experimentation Tool, 2020 International Conference on Social Computing, Behavioral-Cultural Modeling & Prediction and Behavior Representation in Modeling and Simulation, Washington DC.
epiworldR Type: Fast Agent-Based Epi Models
George G. Vega Yon Derek Meyer | Published Monday, August 26, 2024A flexible framework for Agent-Based Models (ABM), the ‘epiworldR’ package provides methods for prototyping disease outbreaks and transmission models using a ‘C++’ backend, making it very fast. It supports multiple epidemiological models, including the Susceptible-Infected-Susceptible (SIS), Susceptible-Infected-Removed (SIR), Susceptible-Exposed-Infected-Removed (SEIR), and others, involving arbitrary mitigation policies and multiple-disease models. Users can specify infectiousness/susceptibility rates as a function of agents’ features, providing great complexity for the model dynamics. Furthermore, ‘epiworldR’ is ideal for simulation studies featuring large populations.
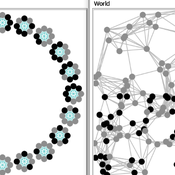
Two agent-based models of cooperation in dynamic groups and fixed social networks
Carlos A. de Matos Fernandes | Published Thursday, January 20, 2022Both models simulate n-person prisoner dilemma in groups (left figure) where agents decide to C/D – using a stochastic threshold algorithm with reinforcement learning components. We model fixed (single group ABM) and dynamic groups (bad-barrels ABM). The purpose of the bad-barrels model is to assess the impact of information during meritocratic matching. In the bad-barrels model, we incorporated a multidimensional structure in which agents are also embedded in a social network (2-person PD). We modeled a random and homophilous network via a random spatial graph algorithm (right figure).
The Effectiveness of Image-Scoring Under Different Ecological Conditions
G M Leighton | Published Monday, January 06, 2014The set of models test how receivers ability to accurately rank signalers under various ecological and behavioral contexts.
Opinion dynamics and collective risk perception: An ABM model of institutional and media communication about disasters - Code and Datasets
danielevilone | Published Tuesday, October 06, 2020The O.R.E. (Opinions on Risky Events) model describes how a population of interacting individuals process information about a risk of natural catastrophe. The institutional information gives the official evaluation of the risk; the agents receive this communication, process it and also speak to each other processing further the information. The description of the algorithm (as it appears also in the paper) can be found in the attached file OREmodel_description.pdf.
The code (ORE_model.c), written in C, is commented. Also the datasets (inputFACEBOOK.txt and inputEMAILs.txt) of the real networks utilized with this model are available.
For any questions/requests, please write me at [email protected]
SiFlo: An Agent-based Model to simulate inhabitants’ behavior during a flood event
Franck Taillandier Pascal Di Maiolo Patrick Taillandier Rasool Mehdizadeh | Published Thursday, July 29, 2021SiFlo is an ABM dedicated to simulate flood events in urban areas. It considers the water flowing and the reaction of the inhabitants. The inhabitants would be able to perform different actions regarding the flood: protection (protect their house, their equipment and furniture…), evacuation (considering traffic model), get and give information (considering imperfect knowledge), etc. A special care was taken to model the inhabitant behavior: the inhabitants should be able to build complex reasoning, to have emotions, to follow or not instructions, to have incomplete knowledge about the flood, to interfere with other inhabitants, to find their way on the road network. The model integrates the closure of roads and the danger a flooded road can represent. Furthermore, it considers the state of the infrastructures and notably protection infrastructures as dyke. Then, it allows to simulate a dyke breaking.
The model intends to be generic and flexible whereas provide a fine geographic description of the case study. In this perspective, the model is able to directly import GIS data to reproduce any territory. The following sections expose the main elements of the model.
Replication of an agent-based model using the Replication Standard
Jiaxin Zhang Derek Robinson | Published Sunday, January 20, 2019 | Last modified Saturday, July 18, 2020This model is a replication model which is constructed based on the existing model used by the following article:
Brown, D.G. and Robinson, D.T., 2006. Effects of heterogeneity in residential preferences on an agent-based model of urban sprawl. Ecology and society, 11(1).
The original model is called SLUCE’s Original Model for Experimentation (SOME). In Brown and Robinson (2006)’s article, the SOME model was used to explore the impacts of heterogeneity in residential location selections on the research of urban sprawl. The original model was constructed using Objective-C language based on SWARM platform. This replication model is built by NetLogo language on NetLogo platform. We successfully replicate that model and demonstrated the reliability and replicability of it.

The purpose of the study is to unpack and explore a potentially beneficial role of sharing metacognitive information within a group when making repeated decisions about common pool resource (CPR) use.
We explore the explanatory power of sharing metacognition by varying (a) the individual errors in judgement (myside-bias); (b) the ways of reaching a collective judgement (metacognition-dependent), (c) individual knowledge updating (metacognition- dependent) and d) the decision making context.
The model (AgentEx-Meta) represents an extension to an existing and validated model reflecting behavioural CPR laboratory experiments (Schill, Lindahl & Crépin, 2015; Lindahl, Crépin & Schill, 2016). AgentEx-Meta allows us to systematically vary the extent to which metacognitive information is available to agents, and to explore the boundary conditions of group benefits of metacognitive information.
An Agent-Based Model of an Insurance Market driven by Supply and Demand with Imperfectly Estimated Strategies in C#
Rei England | Published Sunday, September 24, 2023This is a simulation of an insurance market where the premium moves according to the balance between supply and demand. In this model, insurers set their supply with the aim of maximising their expected utility gain while operating under imperfect information about both customer demand and underlying risk distributions.
There are seven types of insurer strategies. One type follows a rational strategy within the bounds of imperfect information. The other six types also seek to maximise their utility gain, but base their market expectations on a chartist strategy. Under this strategy, market premium is extrapolated from trends based on past insurance prices. This is subdivided according to whether the insurer is trend following or a contrarian (counter-trend), and further depending on whether the trend is estimated from short-term, medium-term, or long-term data.
Customers are modelled as a whole and allocated between insurers according to available supply. Customer demand is calculated according to a logit choice model based on the expected utility gain of purchasing insurance for an average customer versus the expected utility gain of non-purchase.
Displaying 10 of 216 results for "Daniel C Peart" clear search