About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 72 results values clear search
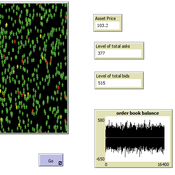
Peer reviewed A financial market with zero intelligence agents
edgarkp | Published Wednesday, March 27, 2024The model’s aim is to represent the price dynamics under very simple market conditions, given the values adopted by the user for the model parameters. We suppose the market of a financial asset contains agents on the hypothesis they have zero-intelligence. In each period, a certain amount of agents are randomly selected to participate to the market. Each of these agents decides, in a equiprobable way, between proposing to make a transaction (talk = 1) or not (talk = 0). Again in an equiprobable way, each participating agent decides to speak on the supply (ask) or the demand side (bid) of the market, and proposes a volume of assets, where this number is drawn randomly from a uniform distribution. The granularity depends on various factors, including market conventions, the type of assets or goods being traded, and regulatory requirements. In some markets, high granularity is essential to capture small price movements accurately, while in others, coarser granularity is sufficient due to the nature of the assets or goods being traded
Peer reviewed An extended replication of Abelson's and Bernstein's community referendum simulation
Klaus G. Troitzsch | Published Friday, October 25, 2019 | Last modified Friday, August 25, 2023This is an extended replication of Abelson’s and Bernstein’s early computer simulation model of community referendum controversies which was originally published in 1963 and often cited, but seldom analysed in detail. This replication is in NetLogo 6.3.0, accompanied with an ODD+D protocol and class and sequence diagrams.
This replication replaces the original scales for attitude position and interest in the referendum issue which were distributed between 0 and 1 with values that are initialised according to a normal distribution with mean 0 and variance 1 to make simulation results easier compatible with scales derived from empirical data collected in surveys such as the European Value Study which often are derived via factor analysis or principal component analysis from the answers to sets of questions.
Another difference is that this model is not only run for Abelson’s and Bernstein’s ten week referendum campaign but for an arbitrary time in order that one can find out whether the distributions of attitude position and interest in the (still one-dimensional) issue stabilise in the long run.
Peer reviewed Dynamic Value-based Cognitive Architectures
Bart de Bruin | Published Tuesday, November 30, 2021The intention of this model is to create an universal basis on how to model change in value prioritizations within social simulation. This model illustrates the designing of heterogeneous populations within agent-based social simulations by equipping agents with Dynamic Value-based Cognitive Architectures (DVCA-model). The DVCA-model uses the psychological theories on values by Schwartz (2012) and character traits by McCrae and Costa (2008) to create an unique trait- and value prioritization system for each individual. Furthermore, the DVCA-model simulates the impact of both social persuasion and life-events (e.g. information, experience) on the value systems of individuals by introducing the innovative concept of perception thermometers. Perception thermometers, controlled by the character traits, operate as buffers between the internal value prioritizations of agents and their external interactions. By introducing the concept of perception thermometers, the DVCA-model allows to study the dynamics of individual value prioritizations under a variety of internal and external perturbations over extensive time periods. Possible applications are the use of the DVCA-model within artificial sociality, opinion dynamics, social learning modelling, behavior selection algorithms and social-economic modelling.

Peer reviewed JuSt-Social COVID-19
Jennifer Badham | Published Thursday, June 18, 2020 | Last modified Monday, March 29, 2021NetLogo model that allows scenarios concerning general social distancing, shielding of high-risk individuals, and informing contacts when symptomatic. Documentation includes a user manual with some simple scenarios, and technical information including descriptions of key procedures and parameter values.
Peer reviewed Gregarious Behavior, Human Colonization and Social Differentiation Agent-Based Model
Sebastian Fajardo Andrés Bernal Gert Jan Hofstede Mark R Kramer Martijn de Vries | Published Thursday, August 20, 2020 | Last modified Thursday, October 29, 2020Studies of colonization processes in past human societies often use a standard population model in which population is represented as a single quantity. Real populations in these processes, however, are structured with internal classes or stages, and classes are sometimes created based on social differentiation. In this present work, information about the colonization of old Providence Island was used to create an agent-based model of the colonization process in a heterogeneous environment for a population with social differentiation. Agents were socially divided into two classes and modeled with dissimilar spatial clustering preferences. The model and simulations assessed the importance of gregarious behavior for colonization processes conducted in heterogeneous environments by socially-differentiated populations. Results suggest that in these conditions, the colonization process starts with an agent cluster in the largest and most suitable area. The spatial distribution of agents maintained a tendency toward randomness as simulation time increased, even when gregariousness values increased. The most conspicuous effects in agent clustering were produced by the initial conditions and behavioral adaptations that increased the agent capacity to access more resources and the likelihood of gregariousness. The approach presented here could be used to analyze past human colonization events or support long-term conceptual design of future human colonization processes with small social formations into unfamiliar and uninhabited environments.
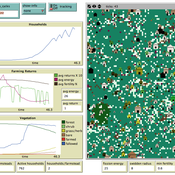
Peer reviewed Swidden Farming Version 2.0
C Michael Barton | Published Wednesday, June 12, 2013 | Last modified Wednesday, September 03, 2014Model of shifting cultivation. All parameters can be controlled by the user or the model can be run in adaptive mode, in which agents innovate and select parameters.

Peer reviewed Axelrod_Cultural_Dissemination
Arezky Hernández | Published Wednesday, March 27, 2013 | Last modified Sunday, May 05, 2013The Axelrod’s model of cultural dissemination is an agent-model designed to investigate the dissemination of culture among interacting agents on a society.
The emergence of tag-mediated altruism in structured societies
Shade Shutters David Hales | Published Tuesday, January 20, 2015 | Last modified Thursday, March 02, 2023This abstract model explores the emergence of altruistic behavior in networked societies. The model allows users to experiment with a number of population-level parameters to better understand what conditions contribute to the emergence of altruism.
Peer reviewed A Simple Agent-Based Spatial Model of the Economy: Tools for Policy
Bernardo Furtado Isaque Daniel Rocha Eberhardt | Published Tuesday, July 05, 2022This study simulates the evolution of artificial economies in order to understand the tax relevance of administrative boundaries in the quality of life of its citizens. The modeling involves the construction of a computational algorithm, which includes citizens, bounded into families; firms and governments; all of them interacting in markets for goods, labor and real estate. The real estate market allows families to move to dwellings with higher quality or lower price when the families capitalize property values. The goods market allows consumers to search on a flexible number of firms choosing by price and proximity. The labor market entails a matching process between firms (given its location) and candidates, according to their qualification. The government may be configured into one, four or seven distinct sub-national governments, which are all economically conurbated. The role of government is to collect taxes on the value added of firms in its territory and invest the taxes into higher levels of quality of life for residents. The results suggest that the configuration of administrative boundaries is relevant to the levels of quality of life arising from the reversal of taxes. The model with seven regions is more dynamic, but more unequal and heterogeneous across regions. The simulation with only one region is more homogeneously poor. The study seeks to contribute to a theoretical and methodological framework as well as to describe, operationalize and test computer models of public finance analysis, with explicitly spatial and dynamic emphasis. Several alternatives of expansion of the model for future research are described. Moreover, this study adds to the existing literature in the realm of simple microeconomic computational models, specifying structural relationships between local governments and firms, consumers and dwellings mediated by distance.
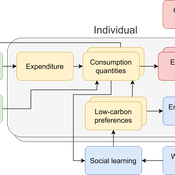
The cultural multiplier of climate policy
Daniel Torren-Peraire | Published Thursday, October 31, 2024For deep decarbonisation, the design of climate policy needs to account for consumption choices being influenced not only by pricing but also by social learning. This involves changes that pertain to the whole spectrum of consumption, possibly involving shifts in lifestyles. In this regard, it is crucial to consider not just short-term social learning processes but also slower, longer-term, cultural change. Against this background, we analyse the interaction between climate policy and cultural change, focusing on carbon taxation. We extend the notion of “social multiplier” of environmental policy derived in an earlier study to the context of multiple consumer needs while allowing for behavioural spillovers between these, giving rise to a “cultural multiplier”. We develop a model to assess how this cultural multiplier contributes to the effectiveness of carbon taxation. Our results show that the cultural multiplier stimulates greater low-carbon consumption compared to fixed preferences. The model results are of particular relevance for policy acceptance due to the cultural multiplier being most effective at low-carbon tax values, relative to a counter-case of short-term social interactions. Notably, at high carbon tax levels, the distinction between social and cultural multiplier effects diminishes, as the strong price signal drives even resistant individuals toward low-carbon consumption. By varying socio-economic conditions, such as substitutability between low- and high-carbon goods, social network structure, proximity of like-minded individuals and the richness of consumption lifestyles, the model provides insight into how cultural change can be leveraged to induce maximum effectiveness of climate policy.
Displaying 10 of 72 results values clear search