About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 8 of 18 results for "Eva Schlecht" clear search
MERCURY extension: population
Tom Brughmans | Published Thursday, May 23, 2019This model is an extended version of the original MERCURY model (https://www.comses.net/codebases/4347/releases/1.1.0/ ) . It allows for experiments to be performed in which empirically informed population sizes of sites are included, that allow for the scaling of the number of tableware traders with the population of settlements, and for hypothesised production centres of four tablewares to be used in experiments.
Experiments performed with this population extension and substantive interpretations derived from them are published in:
Hanson, J.W. & T. Brughmans. In press. Settlement scale and economic networks in the Roman Empire, in T. Brughmans & A.I. Wilson (ed.) Simulating Roman Economies. Theories, Methods and Computational Models. Oxford: Oxford University Press.
…
Peer reviewed BAM: The Bottom-up Adaptive Macroeconomics Model
Alejandro Guerra-Hernández Alejandro Platas López | Published Tuesday, January 14, 2020 | Last modified Sunday, July 26, 2020Overview
Purpose
Modeling an economy with stable macro signals, that works as a benchmark for studying the effects of the agent activities, e.g. extortion, at the service of the elaboration of public policies..
…
Exploring Urban Shrinkage
Andrew Crooks | Published Thursday, March 19, 2020While the world’s total urban population continues to grow, this growth is not equal. Some cities are declining, resulting in urban shrinkage which is now a global phenomenon. Many problems emerge due to urban shrinkage including population loss, economic depression, vacant properties and the contraction of housing markets. To explore this issue, this paper presents an agent-based model stylized on spatially explicit data of Detroit Tri-county area, an area witnessing urban shrinkage. Specifically, the model examines how micro-level housing trades impact urban shrinkage by capturing interactions between sellers and buyers within different sub-housing markets. The stylized model results highlight not only how we can simulate housing transactions but the aggregate market conditions relating to urban shrinkage (i.e., the contraction of housing markets). To this end, the paper demonstrates the potential of simulation to explore urban shrinkage and potentially offers a means to test polices to alleviate this issue.
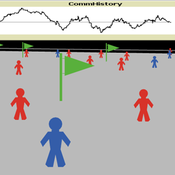
Model of communication between two groups of managers in the course of project implementation
Smarzhevskiy Ivan | Published Monday, December 07, 2020This is a simulation model of communication between two groups of managers in the course of project implementation. The “world” of the model is a space of interaction between project participants, each of which belongs either to a group of work performers or to a group of customers. Information about the progress of the project is publicly available and represents the deviation Earned value (EV) from the planned project value (cost baseline).
The key elements of the model are 1) persons belonging to a group of customers or performers, 2) agents that are communication acts. The life cycle of persons is equal to the time of the simulation experiment, the life cycle of the communication act is 3 periods of model time (for the convenience of visualizing behavior during the experiment). The communication act occurs at a specific point in the model space, the coordinates of which are realized as random variables. During the experiment, persons randomly move in the model space. The communication act involves persons belonging to a group of customers and a group of performers, remote from the place of the communication act at a distance not exceeding the value of the communication radius (MaxCommRadius), while at least one representative from each of the groups must participate in the communication act. If none are found, the communication act is not carried out. The number of potential communication acts per unit of model time is a parameter of the model (CommPerTick).
The managerial sense of the feedback is the stimulating effect of the positive value of the accumulated communication complexity (positive background of the project implementation) on the productivity of the performers. Provided there is favorable communication (“trust”, “mutual understanding”) between the customer and the contractor, it is more likely that project operations will be performed with less lag behind the plan or ahead of it.
The behavior of agents in the world of the model (change of coordinates, visualization of agents’ belonging to a specific communicative act at a given time, etc.) is not informative. Content data are obtained in the form of time series of accumulated communicative complexity, the deviation of the earned value from the planned value, average indicators characterizing communication - the total number of communicative acts and the average number of their participants, etc. These data are displayed on graphs during the simulation experiment.
The control elements of the model allow seven independent values to be varied, which, even with a minimum number of varied values (three: minimum, maximum, optimum), gives 3^7 = 2187 different variants of initial conditions. In this case, the statistical processing of the results requires repeated calculation of the model indicators for each grid node. Thus, the set of varied parameters and the range of their variation is determined by the logic of a particular study and represents a significant narrowing of the full set of initial conditions for which the model allows simulation experiments.
…
Exploring the Effects of Link Recommendations on Social Networks
Ciara Sibley Andrew Crooks | Published Thursday, March 19, 2020The purpose of this model is explore how “friend-of-friend” link recommendations, which are commonly used on social networking sites, impact online social network structure. Specifically, this model generates online social networks, by connecting individuals based upon varying proportions of a) connections from the real world and b) link recommendations. Links formed by recommendation mimic mutual connection, or friend-of-friend algorithms. Generated networks can then be analyzed, by the included scripts, to assess the influence that different proportions of link recommendations have on network properties, specifically: clustering, modularity, path length, eccentricity, diameter, and degree distribution.
Simulation of the Long-term Effects of Decentralized and Adaptive Investments in Cross-agency Interoperable and Standard Systems
Sungho Lee | Published Sunday, May 10, 2009 | Last modified Saturday, April 27, 2013Agent-based model using Blanche software 4.6.5. Blanche software is included in the dataset file.
This model extends the original Artifical Anasazi (AA) model to include individual agents, who vary in age and sex, and are aggregated into households. This allows more realistic simulations of population dynamics within the Long House Valley of Arizona from AD 800 to 1350 than are possible in the original model. The parts of this model that are directly derived from the AA model are based on Janssen’s 1999 Netlogo implementation of the model; the code for all extensions and adaptations in the model described here (the Artificial Long House Valley (ALHV) model) have been written by the authors. The AA model included only ideal and homogeneous “individuals” who do not participate in the population processes (e.g., birth and death)–these processes were assumed to act on entire households only. The ALHV model incorporates actual individual agents and all demographic processes affect these individuals. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. Thus, the ALHV model is a combination of individual processes (birth and death) and household-level processes (e.g., finding suitable agriculture plots).
As is the case for the AA model, the ALHV model makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original model (from Janssen’s Netlogo implementation) to estimate annual maize productivity of various agricultural zones within the valley. These estimates are used to determine suitable locations for households and farms during each year of the simulation.
Artificial Long House Valley-Black Mesa
Amy Warren Lisa Sattenspiel | Published Thursday, March 19, 2020This model is an extension of the Artificial Long House Valley (ALHV) model developed by the authors (Swedlund et al. 2016; Warren and Sattenspiel 2020). The ALHV model simulates the population dynamics of individuals within the Long House Valley of Arizona from AD 800 to 1350. Individuals are aggregated into households that participate in annual agricultural and demographic cycles. The present version of the model incorporates features of the ALHV model including realistic age-specific fertility and mortality and, in addition, it adds the Black Mesa environment and population, as well as additional methods to allow migration between the two regions.
As is the case for previous versions of the ALHV model as well as the Artificial Anasazi (AA) model from which the ALHV model was derived (Axtell et al. 2002; Janssen 2009), this version makes use of detailed archaeological and paleoenvironmental data from the Long House Valley and the adjacent areas in Arizona. It also uses the same methods as the original AA model to estimate annual maize productivity of various agricultural zones within the Long House Valley. A new environment and associated methods have been developed for Black Mesa. Productivity estimates from both regions are used to determine suitable locations for households and farms during each year of the simulation.
Displaying 8 of 18 results for "Eva Schlecht" clear search