About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 256 results for "Eckhard Auch" clear search
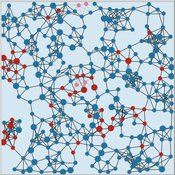
Peer reviewed Virus Transmission with Super-spreaders
J M Applegate | Published Saturday, September 11, 2021A curious aspect of the Covid-19 pandemic is the clustering of outbreaks. Evidence suggests that 80\% of people who contract the virus are infected by only 19% of infected individuals, and that the majority of infected individuals faile to infect another person. Thus, the dispersion of a contagion, $k$, may be of more use in understanding the spread of Covid-19 than the reproduction number, R0.
The Virus Transmission with Super-spreaders model, written in NetLogo, is an adaptation of the canonical Virus Transmission on a Network model and allows the exploration of various mitigation protocols such as testing and quarantines with both homogenous transmission and heterogenous transmission.
The model consists of a population of individuals arranged in a network, where both population and network degree are tunable. At the start of the simulation, a subset of the population is initially infected. As the model runs, infected individuals will infect neighboring susceptible individuals according to either homogenous or heterogenous transmission, where heterogenous transmission models super-spreaders. In this case, k is described as the percentage of super-spreaders in the population and the differing transmission rates for super-spreaders and non super-spreaders. Infected individuals either recover, at which point they become resistant to infection, or die. Testing regimes cause discovered infected individuals to quarantine for a period of time.
Agent-based tax evasion model for investigating impacts of public disclosure
Hiroyuki Sano | Published Thursday, March 14, 2024The model explores the impact of public disclosure on tax compliance among diverse agents, including individual taxpayers and a tax authority. It incorporates heterogeneous preferences and income endowments among taxpayers, captured through a utility function that considers psychic costs subtracted from expected pecuniary utility. These costs include moral, reciprocity, and stigma costs associated with norm violations, leading to variations in taxpayers’ risk attitudes and related parameters. The tax authority’s attributes, such as the frequency of random audits, penalty rate, and the choice between partial or full disclosure, remain fixed throughout the simulation. Income endowments and preference parameters are randomly assigned to taxpayers at the outset.
Taxpayers maximize their expected utility by reporting income, taking into account tax, penalty, and audit rates. They make annual decisions based on their own and their peers’ behaviors from the previous year. Taxpayers indirectly interact at the societal level through public disclosure conducted by the tax authority, exchanging tax information among peers. Each period in the simulation collects data on total reported income, average compliance rates per income group, distribution of compliance rates, counts of compliers, full evaders, partial evaders, and the numbers of taxpayers experiencing guilt and anger. The model evaluates whether public disclosure positively or negatively impacts compliance rates and quantifies this impact based on aggregated individual reporting behaviors.

Peer reviewed Descriptive Norm and Fraud Dynamics
Alexandra Eckert Matthias Meyer Christian Stindt | Published Tuesday, January 07, 2025The “Descriptive Norm and Fraud Dynamics” model demonstrates how fraudulent behavior can either proliferate or be contained within non-hierarchical organizations, such as peer networks, through social influence taking the form of a descriptive norm. This model expands on the fraud triangle theory, which posits that an individual must concurrently possess a financial motive, perceive an opportunity, and hold a pro-fraud attitude to engage in fraudulent activities (red agent). In the absence of any of these elements, the individual will act honestly (green agent).
The model explores variations in a descriptive norm mechanism, ranging from local distorted knowledge to global perfect knowledge. In the case of local distorted knowledge, agents primarily rely on information from their first-degree colleagues. This knowledge is often distorted because agents are slow to update their empirical expectations, which are only partially revised after one-to-one interactions. On the other end of the spectrum, local perfect knowledge is achieved by incorporating a secondary source of information into the agents’ decision-making process. Here, accurate information provided by an observer is used to update empirical expectations.
The model shows that the same variation of the descriptive norm mechanism could lead to varying aggregate fraud levels across different fraud categories. Two empirically measured norm sensitivity distributions associated with different fraud categories can be selected into the model to see the different aggregate outcomes.
A simplified Arthur & Polak logic circuit model of combinatory technology build-out via incremental development. Only some inventions trigger radical effects, suggesting they depend on whole interdependent systems rather than specific innovations.
A Multi-level Multi-model of Collective Motion
Benjamin Camus Christine Bourjot Vincent Chevrier | Published Wednesday, March 25, 2015This multi-model (i.e. a model composed of interacting submodels) is a multi-level representation of a collective motion phenomenon. It was designed to study the impact of the mutual influences between individuals and groups in collective motion.
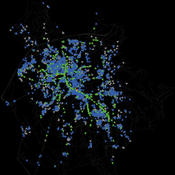
Bicycle encounter model
Gudrun Wallentin | Published Saturday, October 29, 2016 | Last modified Friday, March 29, 2019This Bicycle encounter model builds on the Salzburg Bicycle model (Wallentin & Loidl, 2015). It simulates cyclist flows and encounters, which are locations of potential accidents between cyclists.

Peer reviewed FishCensus
Miguel Pais | Published Tuesday, December 06, 2016 | Last modified Thursday, February 09, 2017The FishCensus model simulates underwater visual census methods, where a diver estimates the abundance of fish. A separate model is used to shape species behaviours and save them to a file that can be shared and used by the counting model.
Hybrid Climate Assessment Model (HCAM)
Peer-Olaf Siebers | Published Friday, February 15, 2019Our Hybrid Climate Assessment Model (HCAM) aims to simulate the behaviours of individuals under the influence of climate change and external policy makings. In our proposed solution we use System Dynamics (SD) modelling to represent the physical and economic environments. Agent-Based (AB) modelling is used to represent collections of individuals that can interact with other collections of individuals and the environment. In turn, individual agents are endowed with an internal SD model to track their psychological state used for decision making. In this paper we address the feasibility of such a scalable hybrid approach as a proof-of-concept. This novel approach allows us to reuse existing rigid, but well-established Integrated Assessment Models (IAMs), and adds more flexibility by replacing aggregate stocks with a community of vibrant interacting entities.
Our illustrative example takes the settings of the U.S., a country that contributes to the majority of the global carbon footprints and that is the largest economic power in the world. The model considers the carbon emission dynamics of individual states and its relevant economic impacts on the nation over time.
Please note that the focus of the model is on a methodological advance rather than on applying it for predictive purposes! More details about the HCAM are provided in the forthcoming JASSS paper “An Innovative Approach to Multi-Method Integrated Assessment Modelling of Global Climate Change”, which is available upon request from the authors (contact [email protected]).
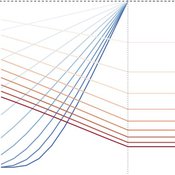
Peer reviewed Price Evolution with Expectations
J M Applegate Gesine Steudel Armin Haas Carlo Jaeger | Published Friday, September 10, 2021The Price Evolution with Expectations model provides the opportunity to explore the question of non-equilibrium market dynamics, and how and under which conditions an economic system converges to the classically defined economic equilibrium. To accomplish this, we bring together two points of view of the economy; the classical perspective of general equilibrium theory and an evolutionary perspective, in which the current development of the economic system determines the possibilities for further evolution.
The Price Evolution with Expectations model consists of a representative firm producing no profit but producing a single good, which we call sugar, and a representative household which provides labour to the firm and purchases sugar.The model explores the evolutionary dynamics whereby the firm does not initially know the household demand but eventually this demand and thus the correct price for sugar given the household’s optimal labour.
The model can be run in one of two ways; the first does not include money and the second uses money such that the firm and/or the household have an endowment that can be spent or saved. In either case, the household has preferences for leisure and consumption and a demand function relating sugar and price, and the firm has a production function and learns the household demand over a set number of time steps using either an endogenous or exogenous learning algorithm. The resulting equilibria, or fixed points of the system, may or may not match the classical economic equilibrium.
Sensitivity of a population submitted to floods to unknown upcoming floods and parameters of the dynamics
Sylvie Huet | Published Wednesday, September 22, 2021This work is a java implementation of a study of the viability of a population submitted to floods. The population derives some benefit from living in a certain environment. However, in this environment, floods can occur and cause damage. An individual protection measure can be adopted by those who wish and have the means to do so. The protection measure reduces the damage in case of a flood. However, the effectiveness of this measure deteriorates over time. Individual motivation to adopt this measure is boosted by the occurrence of a flood. Moreover, the public authorities can encourage the population to adopt this measure by carrying out information campaigns, but this comes at a cost. People’s decisions are modelled based on the Protection Motivation Theory (Rogers1975, Rogers 1997, Maddux1983) arguing that the motivation to protect themselves depends on their perception of risk, their capacity to cope with risk and their socio-demographic characteristics.
While the control designing proper informations campaigns to remain viable every time is computed in the work presented in https://www.comses.net/codebases/e5c17b1f-0121-4461-9ae2-919b6fe27cc4/releases/1.0.0/, the aim of the present work is to produce maps of probable viability in case the serie of upcoming floods is unknown as well as much of the parameters for the population dynamics. These maps are bi-dimensional, based on the value of known parameters: the current average wealth of the population and their actual or possible future annual revenues.
Displaying 10 of 256 results for "Eckhard Auch" clear search