About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 234 results for "Kim Hill" clear search

Exploring social psychology theory for modelling farmer decision-making
James Millington | Published Tuesday, September 18, 2012 | Last modified Saturday, April 27, 2013To investigate the potential of using Social Psychology Theory in ABMs of natural resource use and show proof of concept, we present an exemplary agent-based modelling framework that explicitly represents multiple and hierarchical agent self-concepts
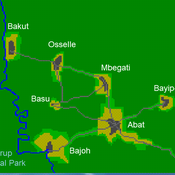
A stylized scale model to codesign with villagers an agent-based model of bushmeat hunting in the periphery of Korup National Park (Cameroon)
Telephone Game
Julia Kasmire | Published Friday, January 10, 2020This is a model of a game of Telephone (also known as Chinese Whishpers in the UK), with agents representing people that can be asked, to play. The first player selects a word from their internal vocabulary and “whispers” it to the next player, who may mishear it depending on the current noise level, who whispers that word to the next player, and so on.
When the game ends, the word chosen by the first player is compared to the word heard by the last player. If they match exactly, all players earn large prize. If the words do not match exactly, a small prize is awarded to all players for each part of the words that do match. Players change color to reflect their current prize-count. A histogram shows the distribution of colors over all the players.
The user can decide on factors like
* how many players there are,
…
Crowdworking Model
Georg Jäger | Published Wednesday, September 25, 2019The purpose of this agent-based model is to compare different variants of crowdworking in a general way, so that the obtained results are independent of specific details of the crowdworking platform. It features many adjustable parameters that can be used to calibrate the model to empirical data, but also when not calibrated it yields essential results about crowdworking in general.
Agents compete for contracts on a virtual crowdworking platform. Each agent is defined by various properties like qualification and income expectation. Agents that are unable to turn a profit have a chance to quit the crowdworking platform and new crowdworkers can replace them. Thus the model has features of an evolutionary process, filtering out the ill suited agents, and generating a realistic distribution of agents from an initially random one. To simulate a stable system, the amount of contracts issued per day can be set constant, as well as the number of crowdworkers. If one is interested in a dynamically changing platform, the simulation can also be initialized in a way that increases or decreases the number of crowdworkers or number of contracts over time. Thus, a large variety of scenarios can be investigated.
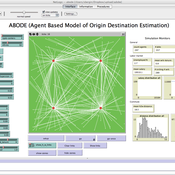
ABODE - Agent Based Model of Origin Destination Estimation
D Levinson | Published Monday, August 29, 2011 | Last modified Saturday, April 27, 2013The agent based model matches origins and destinations using employment search methods at the individual level.
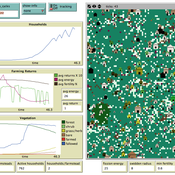
Peer reviewed Swidden Farming Version 2.0
C Michael Barton | Published Wednesday, June 12, 2013 | Last modified Wednesday, September 03, 2014Model of shifting cultivation. All parameters can be controlled by the user or the model can be run in adaptive mode, in which agents innovate and select parameters.
Peer reviewed Collectivities
Nigel Gilbert | Published Tuesday, April 09, 2019 | Last modified Thursday, August 22, 2019The model that simulates the dynamic creation and maintenance of knowledge-based formations such as communities of scientists, fashion movements, and subcultures. The model’s environment is a spatial one, representing not geographical space, but a “knowledge space” in which each point is a different collection of knowledge elements. Agents moving through this space represent people’s differing and changing knowledge and beliefs. The agents have only very simple behaviors: If they are “lonely,” that is, far from a local concentration of agents, they move toward the crowd; if they are crowded, they move away.
Running the model shows that the initial uniform random distribution of agents separates into “clumps,” in which some agents are central and others are distributed around them. The central agents are crowded, and so move. In doing so, they shift the centroid of the clump slightly and may make other agents either crowded or lonely, and they too will move. Thus, the clump of agents, although remaining together for long durations (as measured in time steps), drifts across the view. Lonely agents move toward the clump, sometimes joining it and sometimes continuing to trail behind it. The clumps never merge.
The model is written in NetLogo (v6). It is used as a demonstration of agent-based modelling in Gilbert, N. (2008) Agent-Based Models (Quantitative Applications in the Social Sciences). Sage Publications, Inc. and described in detail in Gilbert, N. (2007) “A generic model of collectivities,” Cybernetics and Systems. European Meeting on Cybernetic Science and Systems Research, 38(7), pp. 695–706.
An Opinion Dynamics of Science? Agent-Based Modeling of Knowledge Spread
Bernardo Buarque | Published Thursday, April 13, 2023We present a socio-epistemic model of science inspired by the existing literature on opinion dynamics. In this model, we embed the agents (or scientists) into social networks - e.g., we link those who work in the same institutions. And we place them into a regular lattice - each representing a unique mental model. Thus, the global environment describes networks of concepts connected based on their similarity. For instance, we may interpret the neighbor lattices as two equivalent models, except one does not include a causal path between two variables.
Agents interact with one another and move across the epistemic lattices. In other words, we allow the agents to explore or travel across the mental models. However, we constrain their movements based on absorptive capacity and cognitive coherence. Namely, in each round, an agent picks a focal point - e.g., one of their colleagues - and will move towards it. But the agents’ ability to move and speed depends on how far apart they are from the focal point - and if their new position is cognitive/logic consistent.
Therefore, we propose an analytical model that examines the connection between agents’ accumulated knowledge, social learning, and the span of attitudes towards mental models in an artificial society. While we rely on the example from the General Theory of Relativity renaissance, our goal is to observe what determines the creation and diffusion of mental models. We offer quantitative and inductive research, which collects data from an artificial environment to elaborate generalized theories about the evolution of science.
Peer reviewed Yards
Emily Minor Soraida Garcia srailsback Philip Johnson | Published Thursday, November 02, 2023This is a model of plant communities in urban and suburban residential neighborhoods. These plant communities are of interest because they provide many benefits to human residents and also provide habitat for wildlife such as birds and pollinators. The model was designed to explore the social factors that create spatial patterns in biodiversity in yards and gardens. In particular, the model was originally developed to determine whether mimicry behaviors–-or neighbors copying each other’s yard design–-could produce observed spatial patterns in vegetation. Plant nurseries and socio-economic constraints were also added to the model as other potential sources of spatial patterns in plant communities.
The idea for the model was inspired by empirical patterns of spatial autocorrelation that have been observed in yard vegetation in Chicago, Illinois (USA), and other cities, where yards that are closer together are more similar than yards that are farther apart. The idea is further supported by literature that shows that people want their yards to fit into their neighborhood. Currently, the yard attribute of interest is the number of plant species, or species richness. Residents compare the richness of their yards to the richness of their neighbors’ yards. If a resident’s yard is too different from their neighbors, the resident will be unhappy and change their yard to make it more similar.
The model outputs information about the diversity and identity of plant species in each yard. This can be analyzed to look for spatial autocorrelation patterns in yard diversity and to explore relationships between mimicry behaviors, yard diversity, and larger scale diversity.

MCR Model
Davide Secchi Nuno R Barros De Oliveira | Published Friday, July 22, 2016 | Last modified Saturday, January 23, 2021The aim of the model is to define when researcher’s assumptions of dependence or independence of cases in multiple case study research affect the results — hence, the understanding of these cases.
Displaying 10 of 234 results for "Kim Hill" clear search