Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 235 results for "Andrea Kaim" clear search
Non-attentional visual information transmission in groups under predation
J. Fransje Weerden, van | Published Wednesday, March 25, 2020Our aim is to show effects of group living when only low-level cognition is assumed, such as pattern recognition needed for normal functioning, without assuming individuals have knowledge about others around them or warn them actively.
The model is of a group of vigilant foragers staying within a patch, under attack by a predator. The foragers use attentional scanning for predator detection, and flee after detection. This fleeing action constitutes a visual cue to danger, and can be received non-attentionally by others if it occurs within their limited visual field. The focus of this model is on the effectiveness of this non-attentional visual information reception.
A blind angle obstructing cue reception caused by behaviour can exist in front, morphology causes a blind angle in the back. These limitations are represented by two visual field shapes. The scan for predators is all-around, with distance-dependent detection; reception of flight cues is limited by visual field shape.
Initial parameters for instance: group sizes, movement, vision characteristics for predator detection and for cue reception. Captures (failure), number of times the information reached all individuals at the same time (All-fled, success), and several other effects of the visual settings are recorded.
Leviathan group model and its approximation
Thibaut Roubin Guillaume Deffuant | Published Tuesday, July 26, 2022The model is based on the influence function of the Leviathan model (Deffuant, Carletti, Huet 2013 and Huet and Deffuant 2017) with the addition of group idenetity. We aim at better explaining some patterns generated by this model, using a derived mathematical approximation of the evolution of the opinions averaged.
We consider agents having an opinion/esteem about each other and about themselves. During dyadic meetings, agents change their respective opinion about each other, and possibly about other agents they gossip about, with a noisy perception of the opinions of their interlocutor. Highly valued agents are more influential in such encounters. Moreover, each agent belongs to a single group and the opinions within the group are attracted to their average.
We show that a group hierarchy can emerges from this model, and that the inequality of reputations among groups have a negative effect on the opinions about the groups of low status. The mathematical analysis of the opinion dynamic shows that the lower the status of the group, the more detrimental the interactions with the agents of other groups are for the opinions about this group, especially when gossip is activated. However, the interactions between agents of the same group tend to have a positive effect on the opinions about this group.

Segregation and Opinion Polarization
Thomas Feliciani Andreas Flache Jochem Tolsma | Published Wednesday, April 13, 2016This is a tool to explore the effects of groups´ spatial segregation on the emergence of opinion polarization. It embeds two opinion formation models: a model of negative (and positive) social influence and a model of persuasive argument exchange.
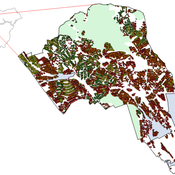
An Agent-Based Model of Flood Risk and Insurance
J Dubbelboer I Nikolic K Jenkins J Hall | Published Monday, July 27, 2015 | Last modified Monday, October 03, 2016A model to show the effects of flood risk on a housing market; the role of flood protection for risk reduction; the working of the existing public-private flood insurance partnership in the UK, and the proposed scheme ‘Flood Re’.
Exploring organizational learning in innovation networks. An agent-based model
Sandra Schmid | Published Saturday, March 07, 2015This agent-based model represents a stylized inter-organizational innovation network where firms collaborate with each other in order to generate novel organizational knowledge.
Ant Colony Optimization for infrastructure routing
Igor Nikolic Emile Chappin P W Heijnen | Published Wednesday, March 05, 2014 | Last modified Saturday, March 24, 2018The mode implements a variant of Ant Colony Optimization to explore routing on infrastructures through a landscape with forbidden zones, connecting multiple sinks to one source.
Scholars have written extensively about hierarchical international order, on the one hand, and war on the other, but surprisingly little work systematically explores the connection between the two. This disconnect is all the more striking given that empirical studies have found a strong relationship between the two. We provide a generative computational network model that explains hierarchy and war as two elements of a larger recursive process: The threat of war drives the formation of hierarchy, which in turn shapes states’ incentives for war. Grounded in canonical theories of hierarchy and war, the model explains an array of known regularities about hierarchical order and conflict. Surprisingly, we also find that many traditional results of the IR literature—including institutional persistence, balancing behavior, and systemic self-regulation—emerge from the interplay between hierarchy and war.

Concession Forestry Modeling
Andrew Bell Daniel G Brown Rick L Riolo Jacqueline M Doremus Thomas P Lyon John Vandermeer Arun Agrawal | Published Thursday, January 23, 2014A logging agent builds roads based on the location of high-value hotspots, and cuts trees based on road access. A forest monitor sanctions the logger on observed infractions, reshaping the pattern of road development.
WOLVES - simulating wolf reappearance in the Netherlands
Kim van Vliet Zoë Delamore | Published Saturday, April 27, 2019This is an agent-based model, simulating wolf (Canis Lupus) reappearance in the Netherlands. The model’s purpose is to allow researchers to investigate the reappearance of wolves in the Netherlands and the possible effect of human interference. Wolf behaviour is modelled according to the literature. The suitability of the Dutch landscape for wolf settlement has been determined by Lelieveld (2012) [1] and is transformed into a colour-coded map of the Netherlands. The colour-coding is the main determinant of wolf settlement. Human involvement is modelled through the public opinion, which varies according to the size, composition and behaviour of the wolf population.
[1] Lelieveld, G.: Room for wolf comeback in the Netherlands, (2012).

Peer reviewed The effect of homophily on co-offending outcomes
Ruslan Klymentiev Christophe Vandeviver Luis E. C. Rocha | Published Friday, September 26, 2025This Agent-Based Model is designed to simulate how similarity-based partner selection (homophily) shapes the formation of co-offending networks and the diffusion of skills within those networks. Its purpose is to isolate and test the effects of offenders’ preference for similar partners on network structure and information flow, under controlled conditions.
In the model, offenders are represented as agents with an individual attribute and a set of skills. At each time step, agents attempt to select partners based on similarity preference. When two agents mutually select each other, they commit a co-offense, forming a tie and exchanging a skill. The model tracks the evolution of network properties (e.g., density, clustering, and tie strength) as well as the spread of skills over time.
This simple and theoretical model does not aim to produce precise empirical predictions but rather to generate insights and test hypotheses about the trade-off between partnership stability and information diffusion. It provides a flexible framework for exploring how changes in partner selection preferences may lead to differences in criminal network dynamics. Although the model was developed to simulate offenders’ interactions, in principle, it could be applied to other social processes involving social learning and skills exchange.
…
Displaying 10 of 235 results for "Andrea Kaim" clear search