Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1207 results for "Aad Kessler" clear search
Will you infect me with your opinion?
Jarosław Miszczak Krzysztof Domino | Published Tuesday, March 15, 2022 | Last modified Monday, August 29, 2022This model incorporates three mechanisms shaping the dynamics of opinion formation, which mimics the dynamics of the virus spreading in the population. There are three methods of getting infected (or convinced) - direct contact, indirect contact, and contact with ``contaminated’’ elements.
Open Peer Review Model
Federico Bianchi | Published Monday, May 24, 2021This is an agent-based model of a population of scientists alternatively authoring or reviewing manuscripts submitted to a scholarly journal for peer review. Peer-review evaluation can be either ‘confidential’, i.e. the identity of authors and reviewers is not disclosed, or ‘open’, i.e. authors’ identity is disclosed to reviewers. The quality of the submitted manuscripts vary according to their authors’ resources, which vary according to the number of publications. Reviewers can assess the assigned manuscript’s quality either reliably of unreliably according to varying behavioural assumptions, i.e. direct/indirect reciprocation of past outcome as authors, or deference towards higher-status authors.
Multi-agent model of the spread of climate change denial
Kalina Maria Piskorska Martin Takáč | Published Monday, March 03, 2025This NetLogo model simulates the spread of climate change beliefs within a population of individuals. Each believer has an initial belief level, which changes over time due to interactions with other individuals and exposure to media. The aim of the model is to identify possible methods for reducing climate change denial.
An agent-based model of adaptive cycles of the spruce budworm
Julia Schindler | Published Saturday, August 18, 2012 | Last modified Saturday, April 27, 2013This is an empirically calibrated agent-based model that replicates spruce-budworm outbreaks, one of the most cited adaptive cycles reported. The adaptive-cycle metaphor by L. H. Gunderson and C. S. Holling posits the cross-case existence of repeating cycles of growth, conservation, collapse, and renewal in many complex systems, triggered by loss of resilience. This model is one of the first agent-based models of such cycles, with the novelty that adaptive cycles are not defined by system- […]
TransportVarese
Elena Vallino Elena Maggi | Published Tuesday, January 31, 2017 | Last modified Friday, August 04, 2017This ABM deals with commuting choices in the Italian city of Varese. Empirical data inform agents’ attitudes and modal choices costs and emissions. We evaluate ex ante the impact of policies for less polluting commuting choices.
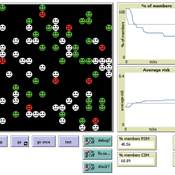
Risk-Sharing under Heterogeneity: NetLogo simulation
Eva Vriens | Published Monday, February 28, 2022Motivated by the emergence of new Peer-to-Peer insurance organizations that rethink how insurance is organized, we propose a theoretical model of decision-making in risk-sharing arrangements with risk heterogeneity and incomplete information about the risk distribution as core features. For these new, informal organisations, the available institutional solutions to heterogeneity (e.g., mandatory participation or price differentiation) are either impossible or undesirable. Hence, we need to understand the scope conditions under which individuals are motivated to participate in a bottom-up risk-sharing setting. The model puts forward participation as a utility maximizing alternative for agents with higher risk levels, who are more risk averse, are driven more by solidarity motives, and less susceptible to cost fluctuations. This basic micro-level model is used to simulate decision-making for agent populations in a dynamic, interdependent setting. Simulation results show that successful risk-sharing arrangements may work if participants are driven by motivations of solidarity or risk aversion, but this is less likely in populations more heterogeneous in risk, as the individual motivations can less often make up for the larger cost deficiencies. At the same time, more heterogeneous groups deal better with uncertainty and temporary cost fluctuations than more homogeneous populations do. In the latter, cascades following temporary peaks in support requests more often result in complete failure, while under full information about the risk distribution this would not have happened.

Peer reviewed General Housing Model
J M Applegate | Published Thursday, May 07, 2020The General Housing Model demonstrates a basic housing market with bank lending, renters, owners and landlords. This model was developed as a base to which students contributed additional functions during Arizona State University’s 2020 Winter School: Agent-Based Modeling of Social-Ecological Systems.
Urban waterlogging disaster evaluation based on complex network a case study of Zhengzhou, China
Chao Ding Jia Xu | Published Monday, April 17, 2023The model constructs a complex network of traffic based on the main urban area of Zhengzhou, China, and simulates the urban rainfall process using the ABM model to analyse the real-time risk of flooding hazards in the nodes of the complex network.
Alternative Fuel Design/Consumer Choice Model
Rosanna Garcia | Published Wednesday, September 22, 2010 | Last modified Saturday, April 27, 2013This is a model of the diffusion of alternative fuel vehicles based on manufacturer designs and consumer choices of those designs. It is written in Netlogo 4.0.3. Because it requires data to upload
Wave When the Hale Wale (WWHW)
María Pereda José Manuel Galán Iván Briz I Godino Jorge Caro Débora Zurro Myriam Álvarez José Santos | Published Friday, October 10, 2014 | Last modified Wednesday, April 25, 2018WWHW is an agent-based model designed to allow the exploration of the emergence, resilience and evolution of cooperative behaviours in hunter-fisher-gatherer societies.
Displaying 10 of 1207 results for "Aad Kessler" clear search