About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 8 of 8 results empirical model clear search

Peer reviewed Share: bottom-up disaster information management
Vittorio Nespeca Tina Comes Frances Brazier | Published Monday, December 05, 2022This model is intended to study the way information is collectively managed (i.e. shared, collected, processed, and stored) in a system and how it performs during a crisis or disaster. Performance is assessed in terms of the system’s ability to provide the information needed to the actors who need it when they need it. There are two main types of actors in the simulation, namely communities and professional responders. Their ability to exchange information is crucial to improve the system’s performance as each of them has direct access to only part of the information they need.
In a nutshell, the following occurs during a simulation. Due to a disaster, a series of randomly occurring disruptive events takes place. The actors in the simulation need to keep track of such events. Specifically, each event generates information needs for the different actors, which increases the information gaps (i.e. the “piles” of unaddressed information needs). In order to reduce the information gaps, the actors need to “discover” the pieces of information they need. The desired behavior or performance of the system is to keep the information gaps as low as possible, which is to address as many information needs as possible as they occur.
An empirical ABM for regional land use/cover change: a Dutch case study
Diego Valbuena | Published Saturday, March 12, 2011 | Last modified Thursday, November 11, 2021This is an empirical model described in http://dx.doi.org/10.1016/j.landurbplan.2010.05.001. The objective of the model is to simulate how the decision-making of farmers/agents with different strategies can affect the landscape structure in a region in the Netherlands.
Collective Decision Making for Ecological Restoration version 2.0
Moira Zellner Dean Massey Cristy Watkins Lynne M Westphal Kristen Ross Jeremy Brooks | Published Wednesday, November 19, 2014CoDMER v. 2.0 was parameterized with ethnographic data from organizations dealing with prescribed fire and seeding native plants, to advance theory on how collective decisions emerge in ecological restoration.
A land-use model to illustrate ambiguity in design
Julia Schindler | Published Monday, October 15, 2012 | Last modified Friday, January 13, 2017This is an agent-based model that allows to test alternative designs for three model components. The model was built using the LUDAS design strategy, while each alternative is in line with the strategy. Using the model, it can be shown that alternative designs, though built on the same strategy, lead to different land-use patterns over time.

A model of circular migration
Anna Klabunde | Published Wednesday, August 07, 2013 | Last modified Wednesday, February 17, 2016An empirically validated agent-based model of circular migration
A consumer-demand simulation for Smart Metering tariffs (Innovation Diffusion)
Martin Rixin | Published Thursday, August 18, 2011 | Last modified Saturday, April 27, 2013An Agent-based model simulates consumer demand for Smart Metering tariffs. It utilizes the Bass Diffusion Model and Rogers´s adopter categories. Integration of empirical census microdata enables a validated socio-economic background for each consumer.
NarrABS
Tilman Schenk | Published Thursday, September 20, 2012 | Last modified Saturday, April 27, 2013An agent based simulation of a political process based on stakeholder narratives
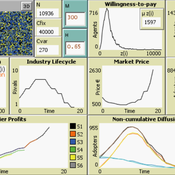
9 Maturity levels in Empirical Validation - An innovation diffusion example
Martin Rixin | Published Wednesday, October 19, 2011 | Last modified Saturday, April 27, 2013Several taxonomies for empirical validation have been published. Our model integrates different methods to calibrate an innovation diffusion model, ranging from simple randomized input validation to complex calibration with the use of microdata.